我有一个编译好的语法,希望用它将输入序列转化为XML。请注意,在我的情况下,我有一份非常庞大的语法规则,我想避免在代码中覆盖每个语法规则。
为了避免混淆,我将使用一个例子。让我们看一个以下的语法规则。
我将其转换为上面展示的XML格式(我使用适用于任何语法的简单通用代码)。我发现这种方法有些笨拙。是否有可能不使用
编辑:
基本上,我需要一种通用的ParseTree序列化方法,以XML格式呈现。主要目标是我不必为每个规则编写特殊的Java序列化方法。
为了避免混淆,我将使用一个例子。让我们看一个以下的语法规则。
grammar expr;
prog: stat+ ;
stat: expr NEWLINE
| ID '=' expr NEWLINE
| NEWLINE
;
expr: expr ('*'|'/') expr
| INT
| ID
| '(' expr ')'
;
ID : [a-zA-Z]+ ; // match identifiers
INT : [0-9]+ ; // match integers
NEWLINE:'\r'? '\n' ; // return newlines to parser (is end-statement signal)
WS : [ \t]+ -> skip ; // toss out whitespace
输入序列
A = 10
B = A * A
预期输出
<prog>
<stat>
A =
<expr> 10
</expr>
\r\n
</stat>
<stat>
B =
<expr>
<expr>A</expr>
*
<expr> A</expr>
</expr>
\r\n
</stat>
</prog>
这对应于解析树
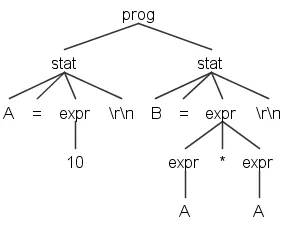
目前,我使用一种方法创建一个ParseTree,并使用toStringTree方法生成以下字符串
(prog (stat A = (expr 10) \r\n) (stat B = (expr (expr A) * (expr A)) \r\n))
我将其转换为上面展示的XML格式(我使用适用于任何语法的简单通用代码)。我发现这种方法有些笨拙。是否有可能不使用
toStringTree来解决它?我想避免需要在我的Visitor中覆盖每个语法规则。(我有数百个语法规则。)编辑:
基本上,我需要一种通用的ParseTree序列化方法,以XML格式呈现。主要目标是我不必为每个规则编写特殊的Java序列化方法。
printXml(ParseTree tree)对ParseTree进行递归下降打印,这个方案怎么样? - Stefan Haustein