我正在使用Python中的nltk和Stanford解析器,并从Stanford Parser and NLTK获得帮助来设置Stanford nlp库。
from nltk.parse.stanford import StanfordParser
from nltk.parse.stanford import StanfordDependencyParser
parser = StanfordParser(model_path="edu/stanford/nlp/models/lexparser/englishPCFG.ser.gz")
dep_parser = StanfordDependencyParser(model_path="edu/stanford/nlp/models/lexparser/englishPCFG.ser.gz")
one = ("John sees Bill")
parsed_Sentence = parser.raw_parse(one)
# GUI
for line in parsed_Sentence:
print line
line.draw()
parsed_Sentence = [parse.tree() for parse in dep_parser.raw_parse(one)]
print parsed_Sentence
# GUI
for line in parsed_Sentence:
print line
line.draw()
我在获取解析和依存树时出现错误,如下例所示,它将“sees”视为名词而不是动词。
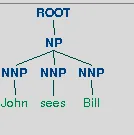

我该怎么做? 当我改变句子时,比如(one = 'John see Bill'),它运行得很完美。这个句子的正确输出可以在这里查看 解析树的正确输出。
以下是正确输出的示例:
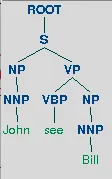

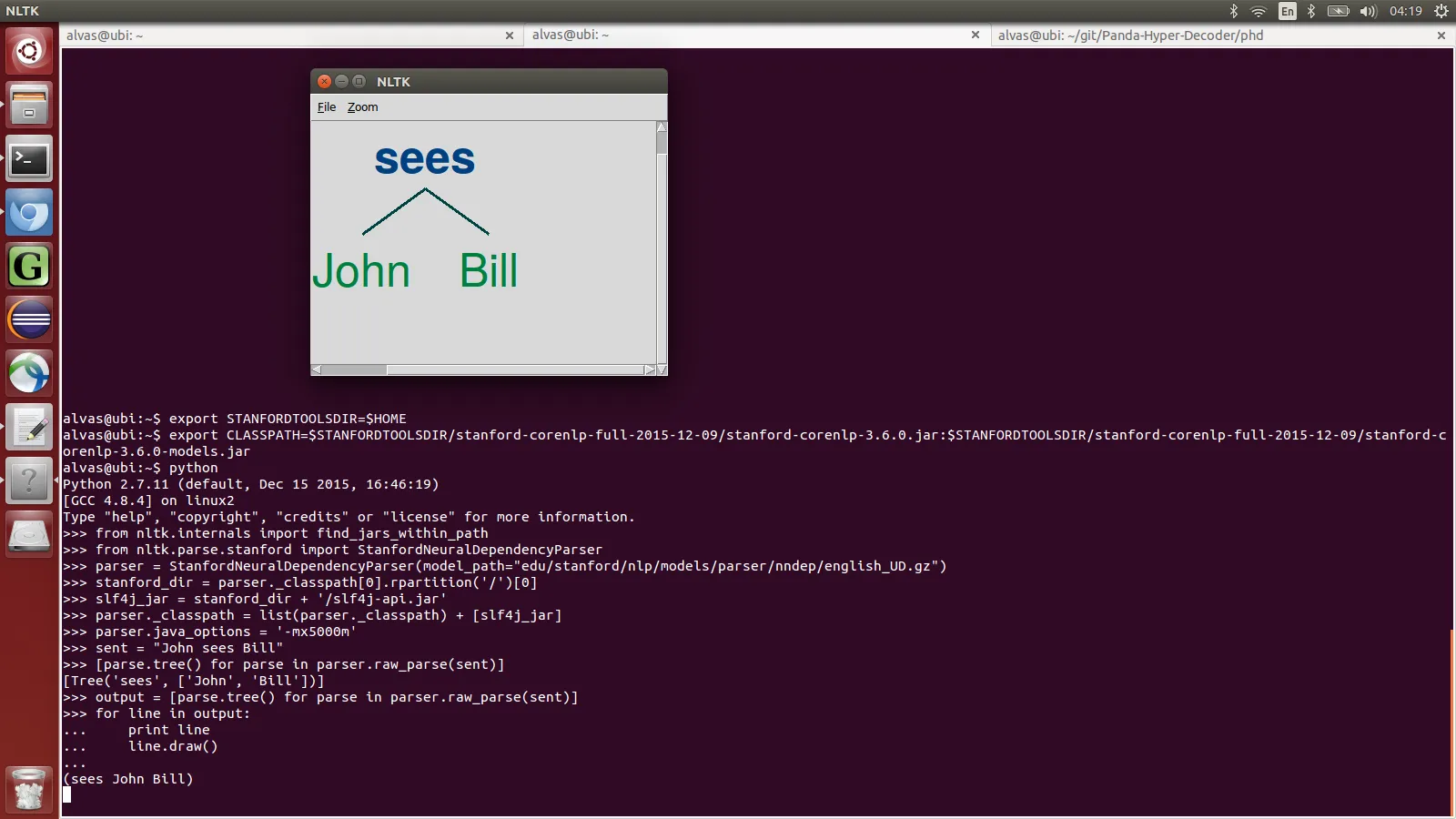
dep_parser的来源 =) - alvas