我们知道,不同的字节序机器在内存中存储对象的顺序从最不重要的字节到最重要的字节有序,而其他机器则从最重要的字节到最不重要的字节存储。例如:一个十六进制值为0x01234567。
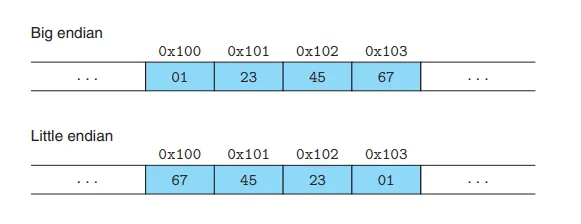
如果我们编写一个打印内存地址中每个字节的C程序,大端和小端机器会产生不同的结果。
但对于字符串,只要使用ASCII作为字符代码,任何系统都可以获得相同的结果,独立于字节顺序和字大小约定。因此,文本数据比二进制数据更具平台无关性。
所以我的问题是,为什么我们针对二进制数据区分大端和小端,我们可以使其与文本数据一样平台无关。在二进制数据中制造大端和小端机器有什么意义?
int16_t或uint16_tC类型)。而且,16位类型对字节序敏感。 - Serge Ballesta