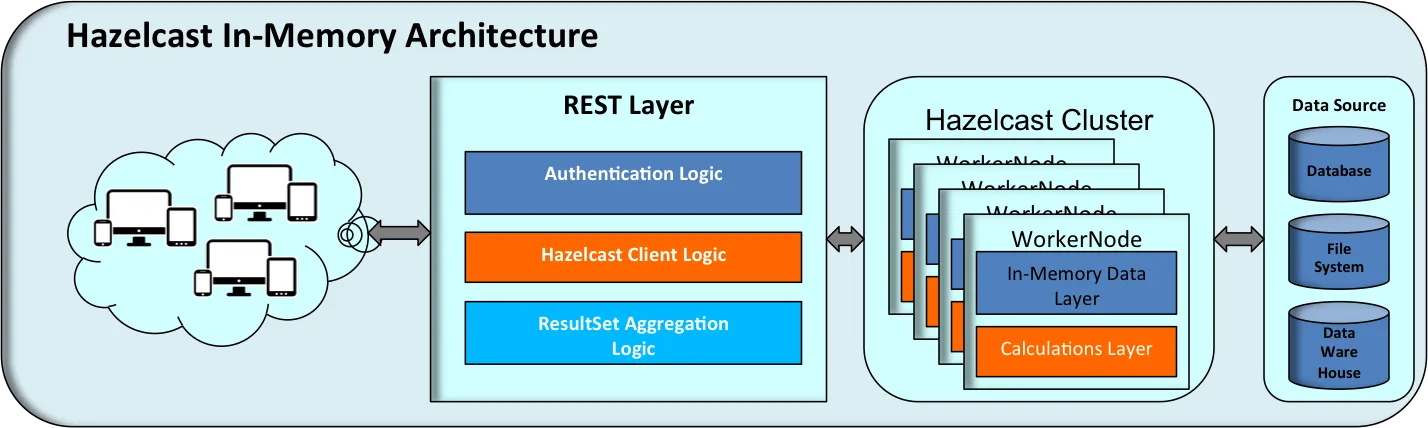
您可以编写一个脚本,运行包含节点启动代码的主类,这样就可以多次运行它。
根据您的用例,我提供了一个示例代码,用于从您的REST客户端驱动程序类创建群集并向所有节点提交任务。
运行下面的类5次,以在TCP/IP配置下创建一个由5个节点组成的群集。
public class WorkerNode {
public static void main(String[] args){
HazelcastInstance workerNode = Hazelcast.newHazelcastInstance();
System.out.println("*********** Started a WorkerNode ***********");
}
}
这里是包含您IO操作业务逻辑的NodeTask。
public class NodeTask implements Callable<Object>, HazelcastInstanceAware, Serializable {
private transient HazelcastInstance hazelcastInstance;
public void setHazelcastInstance(HazelcastInstance hazelcastInstance) {
this.hazelcastInstance = hazelcastInstance;
}
public Object call() throws Exception {
Object returnableObject = "testData";
//Do all the IO operations here and set the returnable object
System.out.println("Running the NodeTask on a Hazelcast Node: " + hazelcastInstance.getName());
return returnableObject;
}
}
以下是您REST客户端的驱动程序类:
public class Driver {
public static void main(String[] args) throws Exception {
HazelcastInstance client = HazelcastClient.newHazelcastClient();
IExecutorService executor = client.getExecutorService("executor");
Map<Member, Future<Object>> result = executor.submitToAllMembers(new NodeTask());
for (Future<Object> future : result.values()) {
System.out.println("Returned data from node: " + future.get());
}
client.shutdown();
System.exit(0);
}
}
示例Hazelcast.xml配置:
<hazelcast xsi:schemaLocation="http://www.hazelcast.com/schema/config http://www.hazelcast.com/schema/config/hazelcast-config-3.8.xsd"
xmlns="http://www.hazelcast.com/schema/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<network>
<port auto-increment="true" port-count="100">5701</port>
<join>
<multicast enabled="false">
<multicast-group>224.2.2.3</multicast-group>
<multicast-port>54327</multicast-port>
</multicast>
<tcp-ip enabled="true">
<interface>127.0.0.1</interface>
</tcp-ip>
<aws enabled="false"/>
</join>
<interfaces enabled="false">
<interface>127.0.0.1</interface>
</interfaces>
</network>
</hazelcast>
submitToKeyOwner不适用于这种情况。我不能使用Spark代替Hazelcast完成此任务 - 它在同时启动两个会话时存在问题。 - VB_