在实现带有单词建议的拼写检查器时,通常使用什么算法?
一开始,我认为对于每个新输入的单词(如果未在字典中找到)进行检查,并将其与字典中的每个单词计算Levenshtein距离,然后返回前几个结果可能是有意义的。但是,这似乎非常低效,需要不断评估整个字典。
通常是如何实现的呢?
在实现带有单词建议的拼写检查器时,通常使用什么算法?
一开始,我认为对于每个新输入的单词(如果未在字典中找到)进行检查,并将其与字典中的每个单词计算Levenshtein距离,然后返回前几个结果可能是有意义的。但是,这似乎非常低效,需要不断评估整个字典。
通常是如何实现的呢?
有一篇Peter Norvig写的好文章介绍如何实现一个拼写纠正器。它基本上是一种暴力破解方法,尝试使用给定的编辑距离生成候选字符串。(这里有一些提示,可以通过使用Bloom过滤器和更快的候选哈希来提高拼写校正器的性能。)
拼写检查器的要求较弱。您只需找出字典中没有该单词即可。您可以使用Bloom过滤器构建拼写检查器,从而消耗更少的内存。Jon Bentley在Programming Pearls中描述了一个古老版本,仅使用64kb的英语字典。
Levenshstein距离并不是一个拼写检查器的完全正确的编辑距离。它只知道插入、删除和替换。转置缺失,对于1个字符的转置会产生2(它包含1个删除和1个插入)。Damerau-Levenshtein距离才是正确的编辑距离。
这个想法是看人们犯的拼写错误类型,并设计哈希函数,使得一个不正确的拼写与其正确的拼写分配到相同的桶中。
例如,常见的错误是使用错误的元音,比如definate 而不是 definite。所以你设计了一个哈希函数,将所有元音字母视为相同的字母。一个简单的方法是先 "规范化" 输入单词,然后将规范化的结果通过常规哈希函数。在这个例子中,规范化函数可能会删除所有元音字母,所以 definite 变成了 dfnt。这个 "规范化" 的单词然后通过一个典型的哈希函数进行哈希。
使用这种特殊哈希函数向辅助索引(哈希表)中插入所有字典单词。由于哈希函数是 "糟糕的",所以这个表中的桶将有较长的冲突列表,但那些冲突列表实质上就是预先计算的建议。
现在,当你找到一个拼错的单词时,查找辅助索引中该错误映射到的桶的冲突列表。哎呀:你有了一个建议列表!你所要做的就是对其上的单词进行排名。
在实践中,你将需要一些带有其他哈希函数的辅助索引来处理其他类型的错误,例如颠倒字母、单/双字母,甚至是类似 Soundex 的简单音标拼写错误。实际上,我发现简单的发音方法可以起到很大的作用,并且本质上使一些旨在查找琐碎的错别字的方法过时了。
因此,现在在每个辅助索引中查找拼写错误,并在排序之前连接冲突列表。
请记住,碰撞列表中仅包含字典中存在的单词。对于试图生成替代拼写的方法(如Peter Norvig文章中所述),您可能会得到(数十)万个候选项,您首先必须将它们与字典进行过滤。使用预先计算的方法,您可能会得到几百个候选项,并且您知道它们都是拼写正确的,因此可以直接跳过筛选步骤进行排名。
更新:我后来找到了一个与此类似的算法描述,即FAROO分布式搜索。这仍然是一个编辑距离有限的搜索,但是由于预计算步骤类似于我的“不良哈希函数”想法,因此非常快速。FAROO只使用了有限的不良哈希函数概念。
您不需要知道字典中每个单词的确切编辑距离。您可以在达到限制值并排除该单词后停止算法。这将节省大量计算时间。
Levenshtein距离递归算法因为重复比较而变得非常缓慢。然后使用wagner-Fisher算法。(它有太多的变体)它使用矩阵来比较字母。
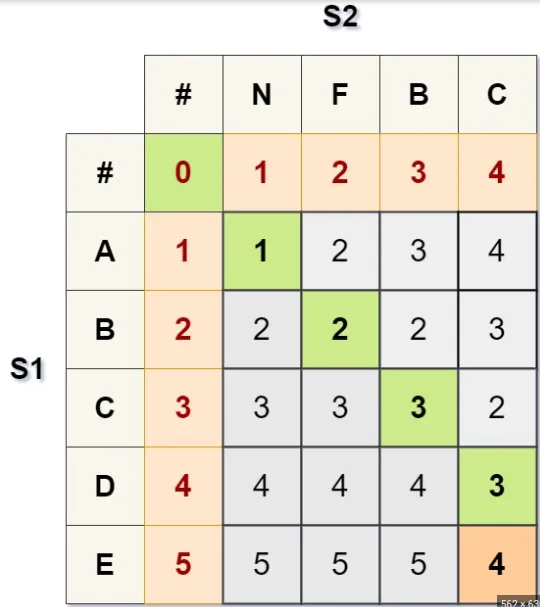
使用3个操作
Insert a character
Delete a character
Replace a character.