我已经苦苦挣扎了一段时间,但似乎找不到解决问题的方法。
问题在于,当我尝试使用Visual Studio 2008下的Nvidia Nsight调试我的CUDA代码时,使用共享内存时会得到奇怪的结果。
我的代码是:
template<typename T>
__device__
T integrate()
{
extern __shared__ T s_test[]; // Dynamically allocated shared memory
/**** Breakpoint (1) here ****/
int index = threadIdx.x + threadIdx.y * blockDim.x; // Local index in block. Column major ordering
if(index < 64 && blockIdx.x==0) { // Only work on a few values. Just testing
s_test[index] = (T)index;
/* Some other irelevant code here */
}
return v;
}
当我到达
断点(1)并在Visual Studio Watch窗口内检查共享内存时,只有数组的前8个值会更改,其他值仍然为空。我希望所有前64个值都这样做。
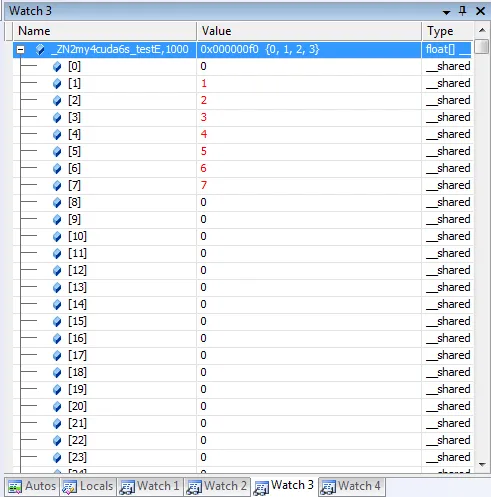
我认为这可能与所有warp不同时执行有关。所以我尝试同步它们。我在integrate()中添加了这段代码。
template<typename T>
__device__
T integrate()
{
/* Old code is still here */
__syncthreads();
/**** Breakpoint (2) here ****/
if(index < 64 && blockIdx.x==0) {
T tmp = s_test[index]; // Write to tmp variable so I can inspect it inside Nsight Watch window
v = tmp + index; // Use `tmp` and `index` somehow so that the compiler doesn't optimize it out of existence
}
return v;
}
但问题仍然存在。此外,
tmp 中的其余值并不像 VS 的监视窗口所示的那样是 0。我必须提到,步过
__syncthreads() 需要很多步骤,因此当我到达它时,我只是跳转到 Breakpoint (2)。发生了什么?
编辑 系统/启动配置信息
系统
- 名称 Intel(R) Core(TM)2 Duo CPU E7300 @ 2.66GHz
- 架构 x86
- 频率 2.666 MHz
- 核心数目 2
- 页面大小 4.096
- 物理内存总量 3,582.00 MB
- 可用物理内存 1,983.00 MB
- 版本名称 Windows 7 Ultimate
- 版本号 6.1.7600
设备 GeForce 9500 GT
- 驱动程序版本 301.42
- 驱动程序模型 WDDM
- CUDA 设备索引 0
- GPU 家族 G96
- 计算能力 1.1
- SM 数量 4
- 帧缓冲物理大小(MB)512
- 帧缓冲带宽(GB/s)16
- 帧缓冲总线宽度(位)128
- 帧缓冲位置 独立
- 图形时钟频率(Mhz)812
- 内存时钟频率(Mhz)500
- 处理器时钟频率(Mhz)1625
- RAM 类型 DDR2
集成开发环境(IDE)
- Microsoft Visual Studio Team System 2008
- NVIDIA Nsight Visual Studio Edition,版本 2.2 Build No. 2.2.0.12255
编译器命令
1> "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v4.2\\bin\nvcc.exe" -G -gencode=arch=compute_10,code=\"sm_10,compute_10\" --machine 32 -ccbin "C:\Program Files\Microsoft Visual Studio 9.0\VC\bin" -D_NEXUS_DEBUG -g -D_DEBUG -Xcompiler "/EHsc /W3 /nologo /Od /Zi /RTC1 /MDd " -I"inc" -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v4.2\\include" -maxrregcount=0 --compile -o "Debug/process_f2f.cu.obj" process_f2f.cu
启动配置。共享内存大小似乎并不重要。我尝试了几个版本。我最常使用的一个是:
- 共享内存2048字节
- 网格/块大小:{101,101,1},{16,16,1}