标准实现 B.Intersect(A).Count() 有很大的优势,因为它简洁易读,除非你有明显的性能问题,否则应该选择它。
当性能成为问题时,您可以引入 HashSet<int>,它在资源使用和搜索时间上是一个不错的折衷方案。但是,由于您担心性能问题,我们应该进行一些测试(我正在使用我编写的这个免费工具):
CPU:1.8 GHz Pentium Core 2 Duo
每个列表中的项目数:1000
迭代次数:100
A.Where(a => B.Contains(a)).Count():8338个滴答声
A.Intersect(B).Count():288个滴答声
B.Count - B.Except(A).Count():313个滴答声
现在让我们在测试中引入 HashSet<int>(从任何其他答案中选择实现):
HashSet<int>:163个滴答声
它表现得更好了。我们能做得更好吗?如果已知输入范围(并且有限),则可以使用 BitArray 比这个快得多。在此示例中,我假设(为简单起见)仅使用正数,但很容易适应其他情况。
public static int UseBitArray(int range, List<int> listA, List<int> listB) {
var BitArray array = new BitArray(range);
for (int i = 0; i < listA.Count; ++i)
array[listA[i]] = true;
int count = 0;
for (int i = 0; i < listB.Count; ++i) {
if (array[listB[i]])
++count;
}
return count;
}
它的性能怎么样?
BitArray: 95个滴答声
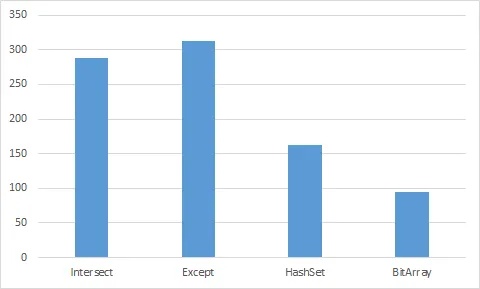
它仅使用了第二佳方法(HashSet<int>)的58%。我甚至不与其他进行比较。请注意,它会严重占用内存,并且对于广泛范围(假设为Int32.MaxValue / 2),它会使用大量内存(此外,它的大小受限于Int32.MaxValue,因此您无法拥有完整的有符号32位整数范围)。如果它的限制对您没有问题,则应该选择它。
还要注意,如果您可以对输入做出一些假设,则可以进一步优化搜索函数(例如,如果您可以假设集合是有序的)。
它们如何扩展(Y轴刻度是对数):
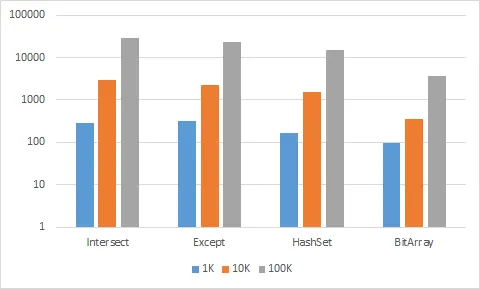
请注意,当项目数量增加时,Except的表现优于Intersect。还要注意,对于这种微不足道的对象(一个整数),并行执行没有任何性能收益(另请参见Finding the difference between two lists of strings):比较是如此微不足道,以至于开销和同步比收益更高(除非它是针对非常多的项目进行了良好调整的算法)。
如果您真的想要最后一点性能提升,甚至可以实现自己的BitArray类(没有不必要的东西和错误检查):
sealed class FastBitArray {
public FastBitArray(int length) {
m_array = new int[((length - 1) / 32) + 1];
}
public bool this[int index] {
get {
return (m_array[index / 32] & (1 << (index % 32))) != 0;
}
set {
if (value)
m_array[index / 32] |= (1 << (index % 32));
else
m_array[index / 32] &= ~(1 << (index % 32));
}
}
private int[] m_array;
}
请注意,在设置器内部有一个分支,我们不必担心优化它,因为模式很简单(始终是true),对于分支预测器来说,没有性能增益使它比这更复杂。
最新测试:
迭代次数:100
每个列表中的项目数:1000000
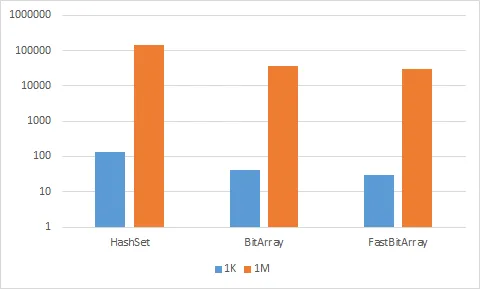
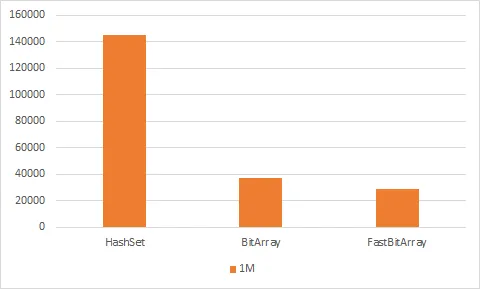
HashSet<int>:144748个时钟周期
BitArray:37292个时钟周期
FastBitArray:28966个时钟周期
让我们以视觉方式进行比较(蓝色系列是1,000项测试,橙色系列是1,000,000项; Y轴是对数以便与1k系列进行比较)。 我们知道速度慢的方法被简单地省略了:
同一数据仅显示1M系列,并带有线性Y轴:
A.Where(x => B.Contains(x)).Count()的意思是在集合A中筛选出所有存在于集合B中的元素,然后计算这些元素的数量。 - tafa