假设有4个表,每个表都包含项目并表示一个集合,如何获得每个区域所需的项目计数,以绘制下面显示的 Venn 图。 计算应在 MySQL 服务器上进行,避免将项目传输到应用程序服务器。
示例表格:
s1: s2: s3: s4:
+------+ +------+ +------+ +------+
| item | | item | | item | | item |
+------+ +------+ +------+ +------+
| a | | a | | a | | a |
+------+ +------+ +------+ +------+
| b | | b | | b | | c |
+------+ +------+ +------+ +------+
| c | | c | | d | | d |
+------+ +------+ +------+ +------+
| d | | e | | e | | e |
+------+ +------+ +------+ +------+
| ... | | ... | | ... | | ... |
现在,我想计算一些集合的幂。以下是一些示例,其中
I对应于s1,II对应于s2,III对应于s3,IV对应于s4: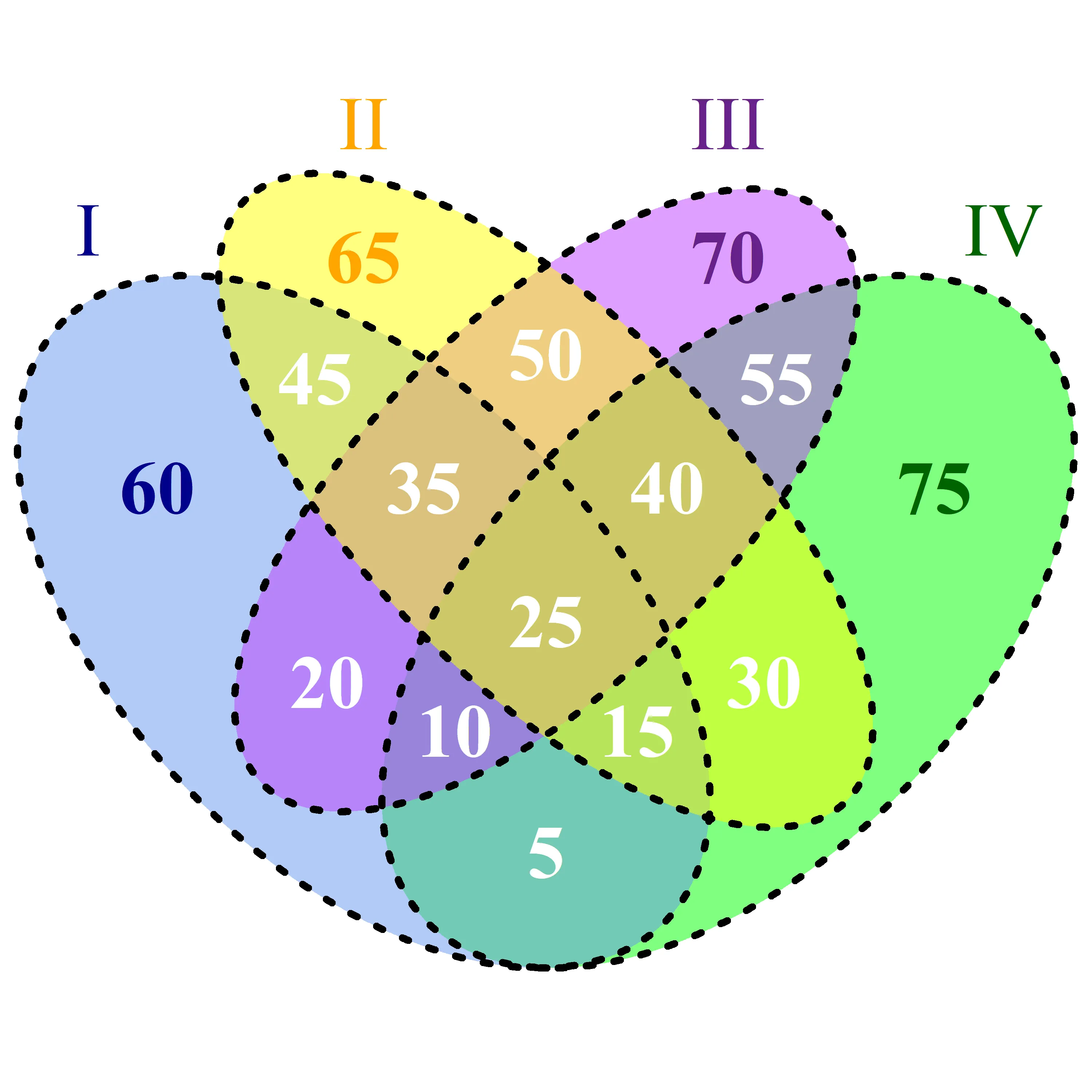
sx重新解释为集合,则会写成:|s1 ∩ s2 ∩ s3 ∩ s4|- 中间的白色25|(s1 ∩ s2 ∩ s4) \ s3|- 关于中心右下角的白色15|(s1 ∩ s4) \ (s2 ∪ s3)|- 底部的白色5|s1 \ (s2 ∪ s3 ∪ s4)|- 蓝色背景上的深蓝色60- ... 直到15。
一种朴素的方法是运行一个查询来计算1。
SELECT count(*) FROM(
SELECT item FROM s1
INTERSECT
SELECT item FROM s2
INTERSECT
SELECT item FROM s3
INTERSECT
SELECT item FROM s4);
还有一个查询需要处理。
SELECT count(*) FROM(
SELECT item FROM s1
INTERSECT
SELECT item FROM s2
INTERSECT
SELECT item FROM s4
EXCEPT
SELECT item FROM s3);
等等,导致了15个查询。
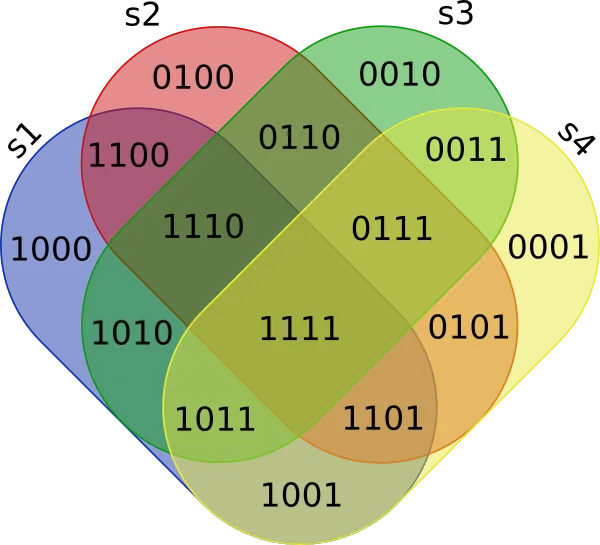
INTERSECT和EXCEPT。因此,您可以使用其他提供这些功能的关系型数据库管理系统。 - Madhur Bhaiya