我希望这是一个可以接受的R/data.table问题。
我有一个三列表格,包括:
- id:地理位置ID(303,453个位置) - month:1990-2014年间的25个月份 - spei:气候指数,变化范围为-7到7。
我需要计算每个位置在整个1990-2014年期间干旱事件的发生次数。干旱事件被定义为“SPEI连续为负且达到-1.0或更低值的时期。当SPEI首次降至零以下时开始出现干旱,并在-1.0或更低值后第一个正SPEI值出现后结束。”
我知道可以使用shift()和rolling joins来实现,但非常希望得到一些帮助!
我有一个三列表格,包括:
- id:地理位置ID(303,453个位置) - month:1990-2014年间的25个月份 - spei:气候指数,变化范围为-7到7。
我需要计算每个位置在整个1990-2014年期间干旱事件的发生次数。干旱事件被定义为“SPEI连续为负且达到-1.0或更低值的时期。当SPEI首次降至零以下时开始出现干旱,并在-1.0或更低值后第一个正SPEI值出现后结束。”
我知道可以使用shift()和rolling joins来实现,但非常希望得到一些帮助!
# Sample table structure
dt <- data.table(
id = rep(1:303453, each=25*12),
month = rep(seq(as.Date("1990-01-01"), as.Date("2014-12-31"), "month"), 303453),
spei = runif(303453*25*12, -7, 7))
# A minimal example with 1 location over 12 months
library(data.table)
library(xts)
dt <- data.table(
id = rep("loc1", each=12),
month = seq(as.Date("2014-01-01"), as.Date("2014-12-31"), "month"),
spei = c(-2, -1.1, -0.5, 1.2, -1.2, 2.3, -1.7, -2.1, 0.9, 1.2, -0.9, -0.2))
spei.ts <- xts(dt$spei, order.by=dt$month, frequency="month")
plot(spei.ts, type="bars")
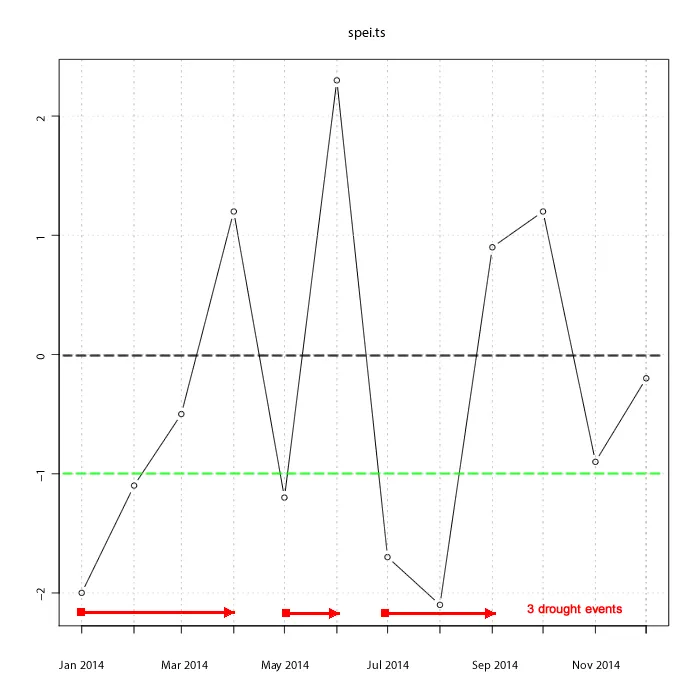
这张图片展示了一个1年期间发生的3次干旱事件。我需要识别并计数这些事件。
希望有些人更习惯于处理时间序列。
非常感谢,--Mel。
rep(1:303453, each=25*12)能否被视为一个小型可重现的示例。 - David Arenburg