我正在创建一个控制台应用程序,它可以执行以下两个操作:
- 连接到供应商API以在两个日期之间获取已提交费用的凭证号码
- 下载与费用提交的收据相关的PDF副本
static async Task RunAsyncCR()
{
using (var client = new HttpClient())
{
var values = new Dictionary<string, string>
{
{"un","SomeUser"},
{"pw","SomePassword"},
{"method","getVoucherInvoices"},
{"fromDate","05/30/2016"},
{"toDate", "06/13/2016"}
};
var content = new FormUrlEncodedContent(values);
Console.WriteLine("Connecting...");
var response = await client.PostAsync("https://www.chromeriver.com/receipts/doit", content);
Console.WriteLine("Connected...");
var responseString = await response.Content.ReadAsStringAsync();
char[] DelimiterChars = {'<'};
String[] xmlReturn = responseString.Split(DelimiterChars);
string[] VoucherNumber = new string[500];
int i = 0;
foreach (string s in xmlReturn)
{
if (s.Contains("voucherInvoice>") && s != "/voucherInvoice>\n ")
{
VoucherNumber[i] = s.Substring(15, 16);
i++;
}
}
Array.Resize(ref VoucherNumber, i);
是的,可能有更好的方法来完成这个任务,但它能够正常工作并返回我期望的值。
现在,我遇到的问题是当我重新连接API以检索文件时,我似乎无法将文件下载到指定的文件路径。
我可以使用以下代码重新连接API:
i = 0;
foreach (string x in VoucherNumber)
{
Console.WriteLine("Get receipt: " + x);
var NewValues = new Dictionary<string, string>
{
{"un","SomeUser"},
{"pw","SomePassword"},
{"method","getReceiptsWithCoverPage"},
{"voucherInvoiceForPdf", VoucherNumber[i]}
};
var NewContent = new FormUrlEncodedContent(NewValues);
var NewResponse = await client.PostAsync("https://www.chromeriver.com/receipts/doit", NewContent);
string NewResponseString = await NewResponse.Content.ReadAsStringAsync();
但是我无法将响应写入有效的文件(PDF)。
这里是我的Autos窗口的屏幕截图,当我逐步执行代码时,我需要下载该文件:
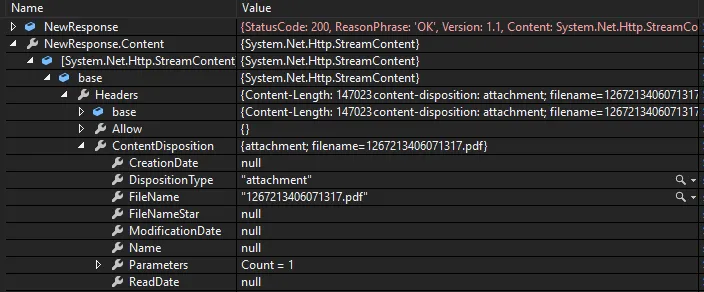
我的问题是,从这个点开始,我该如何将文件保存到我的系统中?
我尝试使用System.IO.File.WriteAllLines()方法获取从Console.WriteLine(NewResponseString);得到的编码响应,并使用指定的文件路径/名称将其写入文件,但结果是空白文件。 我也花了一些时间在谷歌/Stackoverflow上进行深入研究,但是我不知道如何实现我找到的结果。
非常感谢您提供任何帮助。