诚然,我不太理解。假设您有一个内存单元,其内存单元字长为1字节。为什么不能在非对齐地址(即不能被4整除的地址)上通过单次内存访问访问4个字节长的变量,就像对齐地址一样?
内存对齐的目的
276
- Daniel
6
23在进行了一些额外的谷歌搜索后,我找到了这个很棒的链接(http://www.ibm.com/developerworks/library/pa-dalign/),它很好地解释了这个问题。 - Daar
1请查看这篇小文章,适合初学者阅读:http://blog.virtualmethodstudio.com/2017/03/memory-alignment-run-fools/ - Darkgaze
10链接失效。 - John Jiang
10@JohnJiang 我想我在这里找到了新链接:https://developer.ibm.com/technologies/systems/articles/pa-dalign/ - ejohnso49
5截至2022年,@ark提供的链接似乎已经再次更改位置。因此,这是2008年原始页面的快照链接:网络档案馆:数据对齐-挺直身子,向前飞。 - Frederik Hoeft
22023年更新的链接:https://developer.ibm.com/articles/pa-dalign/ - Dennis
8个回答
418
现代处理器的内存子系统受限于以其字大小为粒度和对齐方式访问内存;这是由于多种原因造成的。
速度
现代处理器具有多级缓存内存,数据必须通过这些缓存层传递;支持单字节读取将使内存子系统吞吐量与执行单元吞吐量(也称为CPU限制)紧密绑定;这与硬盘驱动器中的PIO模式被DMA超越的原因非常相似。
CPU 始终以其字大小(32位处理器上为4字节)进行读取,因此当您进行非对齐地址访问时(在支持的处理器上),处理器将读取多个字。 CPU将读取您请求的地址跨越的每个内存字。这会导致所需的内存事务数量增加了最多2倍。
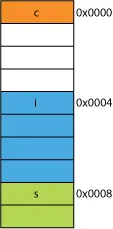
因此,读取两个字节比四个字节更慢非常容易。例如,假设您在内存中有一个如下所示的结构体:
在32位处理器上,它很可能会像这里显示的那样对齐。
假设你有一个结构体的紧凑版本,可能是从网络上打包传输效率而来;它可能看起来像这样:
这甚至可能影响系统的物理设计。如果地址总线需要少2位,CPU上就可以少2个引脚,电路板上也可以少2条线路。
额外福利:缓存
我之前提到的另一个与性能相关的对齐是针对缓存行进行对齐,例如某些CPU上的缓存行大小为64B。
要了解通过利用缓存可以获得多少性能,请参考处理器缓存效果图库;从这个关于缓存行大小的问题开始。
引用: 对于某些类型的程序优化来说,理解缓存行可能很重要。例如,数据的对齐方式可能决定一个操作是否涉及一个或两个缓存行。正如我们在上面的例子中看到的,这很容易意味着在不对齐的情况下,操作速度会慢两倍。
速度
现代处理器具有多级缓存内存,数据必须通过这些缓存层传递;支持单字节读取将使内存子系统吞吐量与执行单元吞吐量(也称为CPU限制)紧密绑定;这与硬盘驱动器中的PIO模式被DMA超越的原因非常相似。
CPU 始终以其字大小(32位处理器上为4字节)进行读取,因此当您进行非对齐地址访问时(在支持的处理器上),处理器将读取多个字。 CPU将读取您请求的地址跨越的每个内存字。这会导致所需的内存事务数量增加了最多2倍。
因此,读取两个字节比四个字节更慢非常容易。例如,假设您在内存中有一个如下所示的结构体:
struct mystruct {
char c; // one byte
int i; // four bytes
short s; // two bytes
}
在32位处理器上,它很可能会像这里显示的那样对齐。
假设你有一个结构体的紧凑版本,可能是从网络上打包传输效率而来;它可能看起来像这样:
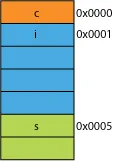
读取第一个字节将是相同的。
当你要求处理器从0x0005给你16位时,它将从0x0004读取一个字并将其左移1个字节放入16位寄存器中;有一些额外的工作,但大多数处理器可以在一个周期内完成。
当你要求从0x0001获取32位时,会得到2倍的放大。处理器将从0x0000读取结果到寄存器中并左移1个字节,然后再次从0x0004读取到临时寄存器中,并右移3个字节,然后与结果寄存器进行OR操作。
范围
对于任何给定的地址空间,如果架构可以假设最低有效位(LSB)始终为0(例如32位机器),那么它可以访问更多的内存(保存的2位可以表示4个不同的状态),或者使用2位来表示类似标志的内容以访问相同数量的内存。从地址中去掉最低的2位将使其按4字节对齐;也称为4字节步长。每次增加一个地址时,实际上是在增加第2位,而不是第0位,即最后的2位将始终保持为“00”。这甚至可能影响系统的物理设计。如果地址总线需要少2位,CPU上就可以少2个引脚,电路板上也可以少2条线路。
原子性
CPU可以原子地操作对齐的内存字,这意味着没有其他指令可以中断该操作。这对于许多无锁数据结构和其他并发编程范例的正确运行至关重要。
结论
处理器的内存系统比此处描述的更为复杂和涉及广泛;论述x86处理器如何实际寻址内存可以提供帮助(许多处理器的工作方式类似)。
遵循内存对齐还有许多其他好处,您可以在这篇IBM文章中阅读到。
计算机的主要用途是转换数据。现代内存架构和技术经过数十年的优化,以高度可靠的方式实现更多数据在更多和更快的执行单元之间的输入、输出和传输。额外福利:缓存
我之前提到的另一个与性能相关的对齐是针对缓存行进行对齐,例如某些CPU上的缓存行大小为64B。
要了解通过利用缓存可以获得多少性能,请参考处理器缓存效果图库;从这个关于缓存行大小的问题开始。
引用: 对于某些类型的程序优化来说,理解缓存行可能很重要。例如,数据的对齐方式可能决定一个操作是否涉及一个或两个缓存行。正如我们在上面的例子中看到的,这很容易意味着在不对齐的情况下,操作速度会慢两倍。
- joshperry
29
1如果我理解正确的话,计算机无法在一步中读取未对齐的字(word)的原因是地址使用了30位而不是32位? - GetFree
2@joshperry:稍作修正:8086可以在四个周期内执行字对齐的16位读取,而非对齐读取需要八个周期。由于缓慢的内存接口,基于8088的机器上执行时间通常由指令获取所占主导地位。像“MOV AX,BX”这样的指令名义上比“XCHG AX,BX”快一个周期,但除非它之前或之后的指令每个代码字节需要执行超过四个周期,否则它将需要多花费四个周期来执行。在8086上,代码获取有时可以跟得上执行,但在8088上,除非使用... - supercat
3我认为
mystruct 的对齐方式不正确。C 结构体总是按照其最大成员的对齐方式进行对齐,因此在 s 后应该有两个额外的填充字节。 - Martin2非常正确,@martin。我省略了那些填充字节,以便将讨论集中在结构内部,但也许最好还是将它们包含进去。 - joshperry
1你是不是指缓存行的64B(字节)? - Leo Heinsaar
显示剩余24条评论
81
这是许多底层处理器的限制。通常可以通过进行4次低效的单字节提取来解决,而不是一次高效的字提取,但许多语言规范决定禁止这种操作,并强制要求所有数据对齐。
OP发现了这个链接中的更多信息。
OP发现了这个链接中的更多信息。
- Paul Tomblin
3
谢谢,@AveMilia,我已经更新了答案。 - Paul Tomblin
此链接不存在 - undefined
@DilipKumar 链接已修复。当我在StackOverflow开始时,从未想过我会维护15年前答案中的链接。 - undefined
31
你可以使用一些处理器(像 Nehalem 处理器),但以前所有的内存访问都是在 64 位(或 32 位)线上对齐的,因为总线宽度是 64 位,所以必须一次获取 64 位,将其按照对齐的 64 位“块”显著更容易获取。
所以,如果你想要一个单字节,你需要获取 64 位块,然后屏蔽掉你不需要的位。如果你需要的字节位于这 64 位块的中间,那么你就得屏蔽掉不需要的位,然后将数据移动到正确的位置。更糟糕的是,如果你需要一个由两个字节变量组成的变量,但它被分割成了两个块,那么就需要双倍的内存访问。
因此,由于所有人都认为内存是廉价的,他们只需让编译器将数据对齐到处理器的块大小,使您的代码以牺牲内存为代价运行更快,更有效率。
- gbjbaanb
4
如果你的字节位于64位块的正确端,那么获取起来就很容易和快速。但是,如果它位于那个64位块的中间,为什么你不能从你的字节所在位置开始获取64位呢? - Mehdi Charife
@MehdiCharife,因为在总线大小的块中实现硬件内存控制器比按字节对齐更容易(因此更便宜,可能也更快)。以块为单位访问更有利于缓存,按字节对齐会使复杂化并且更容易错过缓存。 - gbjbaanb
“块访问更适合缓存”,为什么不能从要读取的字节开始访问块? - Mehdi Charife
你可以提出一个澄清问题,但请不要在评论区问问题。 - gbjbaanb
9
根本原因是内存总线长度比内存大小小得多。
因此,CPU从芯片上的L1缓存中读取数据,这些天通常为32KB。但连接L1缓存和CPU的内存总线的宽度将远远小于缓存行大小。这将在128位左右。
因此:
262,144 bits - size of memory
128 bits - size of bus
不对齐的访问有时会重叠两个缓存行,这将需要一个全新的缓存读取才能获取数据。甚至可能完全错过DRAM。
此外,CPU 的某个部分必须倒立着将这两个不同的缓存行组合成一个单一对象,其中每个对象都有一部分数据。在一行上,它将在非常高的位数中,在另一行上,它将在非常低的位数中。
将专用硬件完全集成到管道中以处理将对齐的对象移动到 CPU 数据总线的必要位上,但是对于不对齐的对象可能缺乏这样的硬件,因为使用这些晶体管加速正确优化的程序可能更有意义。
无论如何,第二个有时必要的内存读取都会减慢管道的速度,无论有多少专用硬件(假设和愚蠢地)专门用于修补不对齐的内存操作。
- DigitalRoss
2
1无论有多少专用硬件(假设和愚蠢地)专门用于修补不对齐的内存操作,现代英特尔CPU,请站起来/挥手。:P 完全有效地处理不对齐的256位AVX负载(只要它们不跨越缓存行边界)对软件非常方便。即使是分裂负载也不太糟糕,Skylake大大改善了页面分割负载/存储的惩罚,从约100个周期降至约10个周期。(如果在不对齐的缓冲区上进行矢量化,并且循环没有花费额外的启动/清理代码来对齐指针,则会发生这种情况) - Peter Cordes
1具有512位路径连接L1d缓存和加载/存储执行单元的AVX512 CPU在处理不对齐指针时会受到显著影响,因为每个负载都是不对齐的,而不是每隔一个。 - Peter Cordes
4
@joshperry已经对这个问题给出了一个很好的答案。除了他的回答之外,我还有一些数字可以图形化地展示所描述的影响,特别是2倍放大效应。这里是一个链接到Google电子表格,展示不同单词对齐方式的效果。 此外,这里还有一个Github gist的链接,其中包含测试代码。 测试代码改编自Jonathan Rentzsch写的文章,@joshperry也引用了这篇文章。这些测试在一台配备四核2.8 GHz Intel Core i7 64位处理器和16GB RAM的Macbook Pro上运行。
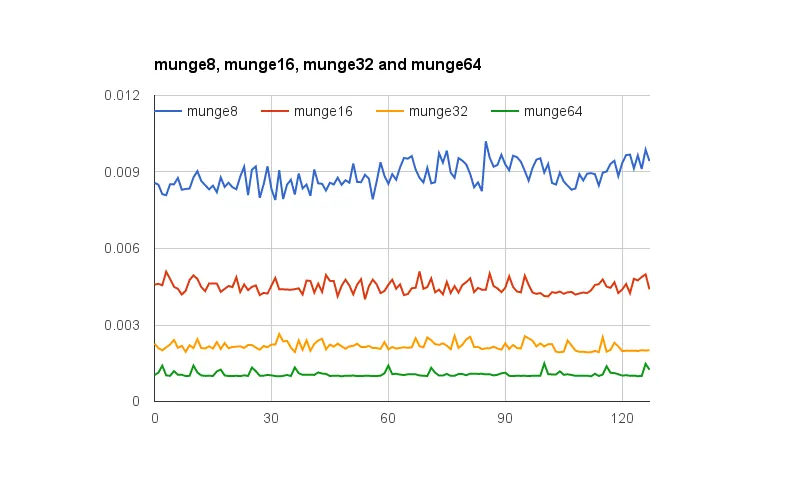
- adino
3
5“x”和“y”坐标是什么意思? - KRoy
2第几代的Core i7?(感谢您发布代码链接!) - Nick Desaulniers
哎呀!memcpy函数是专门针对非对齐数据进行优化的!这样的测试毫无意义! - Kirill Frolov
3
如果您有一个32位数据总线,与内存连接的地址总线地址线将从A2开始,因此在单个总线周期中只能访问32位对齐地址。 因此,如果一个字跨越地址对齐边界 - 即16/32位数据的A0或32位数据的A1不为零,则需要两个总线周期才能获取数据。
一些架构/指令集不支持非对齐访问,并将在此类尝试时生成异常,因此编译器生成的非对齐访问代码不仅需要额外的总线周期,还需要额外的指令,使其效率更低。
一些架构/指令集不支持非对齐访问,并将在此类尝试时生成异常,因此编译器生成的非对齐访问代码不仅需要额外的总线周期,还需要额外的指令,使其效率更低。
- Clifford
2
如果一个具有字节寻址内存的系统拥有32位宽的内存总线,这意味着实际上有四个字节宽的内存系统,所有系统都被连接到读取或写入相同的地址。对齐的32位读取将需要从所有四个内存系统中存储在相同地址的信息,因此所有系统可以同时提供数据。不对齐的32位读取将需要一些内存系统从一个地址返回数据,而另一些则从下一个更高的地址返回数据。虽然有一些内存系统被优化为能够满足这样的请求(除了它们的地址外,它们实际上还有一个“加一”信号,导致它们使用比指定地址高一个的地址),但这种功能会给内存系统增加相当大的成本和复杂性;大多数商品内存系统简单地不能同时返回不同32位字的部分。
- supercat
0
在 PowerPC 上,您可以从奇地址加载整数而没有任何问题。
Sparc 和 I86 以及 (我认为) Itatnium 在尝试此操作时会引发硬件异常。
在大多数现代处理器上,一次32位加载与四次8位加载的区别不会太大。数据是否已经在缓存中将产生更大的影响。
- James Anderson
2
1在 Sparc 上,这被称为“总线错误”,因此在 Peter Van der Linden 的《Expert C Programming:Deep C Secrets》一书中有一个章节名为“总线错误,乘坐火车”。 - jjg
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 19 指向对齐内存的指针
- 4 C++ - 对齐内存
- 7 Java类的内存对齐
- 4 内存对齐
- 26 对齐和未对齐的内存访问?
- 3 不对齐的内存访问
- 10 数组的内存对齐
- 21 对齐内存管理?
- 7 类的内存对齐
- 5 C++内存对齐