我正在尝试解析https://www.tandfonline.com/toc/icbi20/current,获取所有文章的标题。HTML被分为多个卷和期。每个卷都有一个对应月份的期。因此,对于第36卷,将有12期。在当前卷(第37卷)中,有4个期刊,我想遍历每个期刊,并获取每篇文章的名称。
为了实现这一点并自动搜索,我需要获取每个期刊的href链接。最初,我选择了父div id:id = 'tocList'。
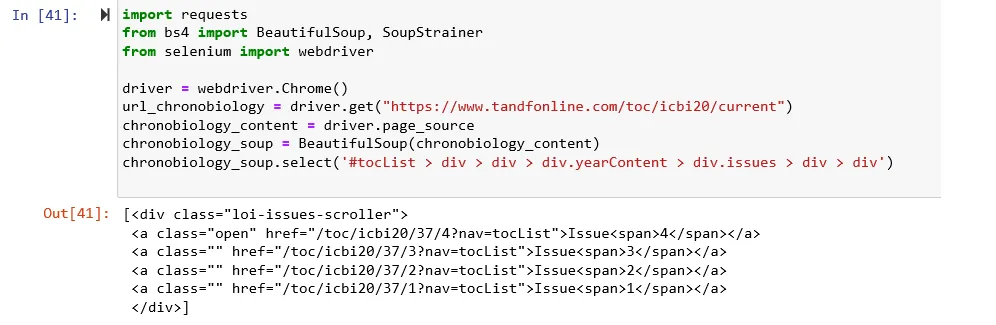
这将返回一个bs4对象,但仅包含来自Volume
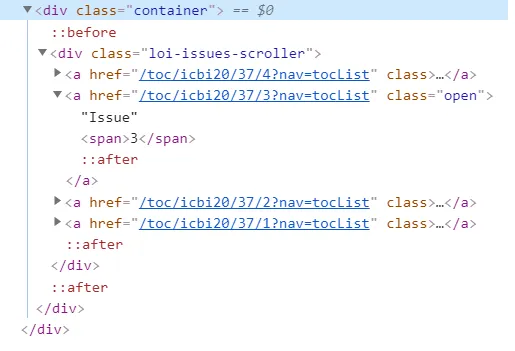
因此,我决定缩小搜索范围并使其更加具体化,并选择包含Issue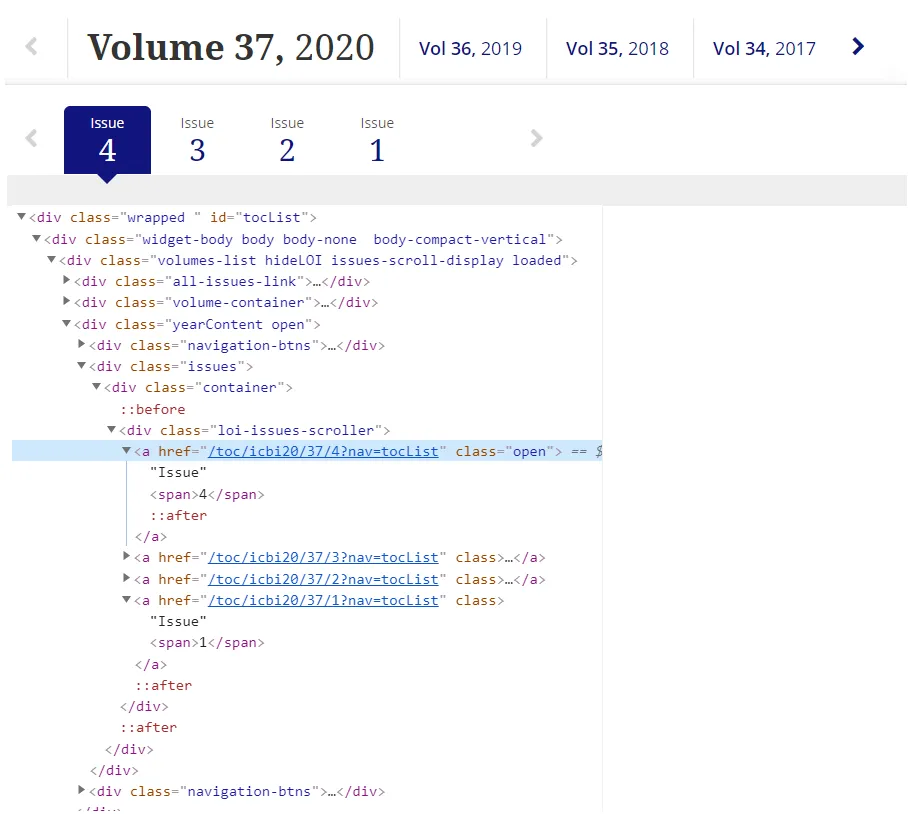 这次Jupiter会思考一下,但不会返回任何东西。什么也没有。空白。无。但是,如果我询问返回的“nothing”类型是什么,jupiter会告诉它是“
这次Jupiter会思考一下,但不会返回任何东西。什么也没有。空白。无。但是,如果我询问返回的“nothing”类型是什么,jupiter会告诉它是“
首先,我有一个问题,为什么Issue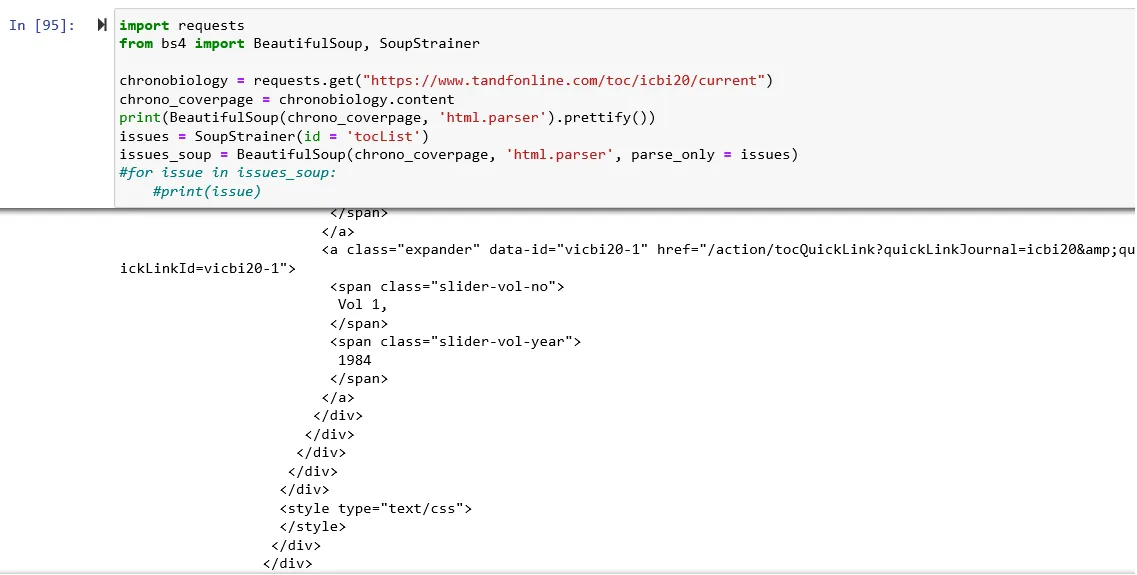 因此,我怀疑它必须是面向javascript或其他东西,而不是面向HTML。或者
因此,我怀疑它必须是面向javascript或其他东西,而不是面向HTML。或者
如何解析通过Javascript链接进行的链接?任何澄清都将不胜感激。
为了实现这一点并自动搜索,我需要获取每个期刊的href链接。最初,我选择了父div id:id = 'tocList'。
import requests
from bs4 import BeautifulSoup, SoupStrainer
chronobiology = requests.get("https://www.tandfonline.com/toc/icbi20/current")
chrono_coverpage = chronobiology.content
issues = SoupStrainer(id ='tocList')
issues_soup = BeautifulSoup(chrono_coverpage, 'html.parser', parse_only = issues)
for issue in issues_soup:
print(issue)
这将返回一个bs4对象,但仅包含来自Volume
div的 href 链接。更糟糕的是,这个 div 应该涵盖Volume div和Issue div。因此,我决定缩小搜索范围并使其更加具体化,并选择包含Issue
href链接(class_='issues')的 div
这次Jupiter会思考一下,但不会返回任何东西。什么也没有。空白。无。但是,如果我询问返回的“nothing”类型是什么,jupiter会告诉它是“String”???我真的不知道如何解释这个。首先,我有一个问题,为什么Issue
div元素不响应解析?
当我尝试运行print(BeautifulSoup(chrono_coverpage,'html.parser') .prettify())时,同样的情况发生了,Issue div不会出现(在html页面上的Inspect Element它立即出现在最终Volume span之下):
因此,我怀疑它必须是面向javascript或其他东西,而不是面向HTML。或者 class ='open' 可能与此有关。如何解析通过Javascript链接进行的链接?任何澄清都将不胜感激。