add_timer以1个jiffy的分辨率(即计时器被安排在jiffies + 1时刻触发)重复调用一个函数10次。使用bash脚本rerun.sh,我可以从syslog的打印输出中获取时间戳,并使用gnuplot进行可视化。大多数情况下,我得到像这样的
syslog输出:[ 7103.055787] Init testjiffy: 0 ; HZ: 250 ; 1/HZ (ms): 4
[ 7103.056044] testjiffy_timer_function: runcount 1
[ 7103.060045] testjiffy_timer_function: runcount 2
[ 7103.064052] testjiffy_timer_function: runcount 3
[ 7103.068050] testjiffy_timer_function: runcount 4
[ 7103.072053] testjiffy_timer_function: runcount 5
[ 7103.076036] testjiffy_timer_function: runcount 6
[ 7103.080044] testjiffy_timer_function: runcount 7
[ 7103.084044] testjiffy_timer_function: runcount 8
[ 7103.088060] testjiffy_timer_function: runcount 9
[ 7103.092059] testjiffy_timer_function: runcount 10
[ 7104.095429] Exit testjiffy
... 这将会生成类似于下面这些的时间序列和增量柱状图:
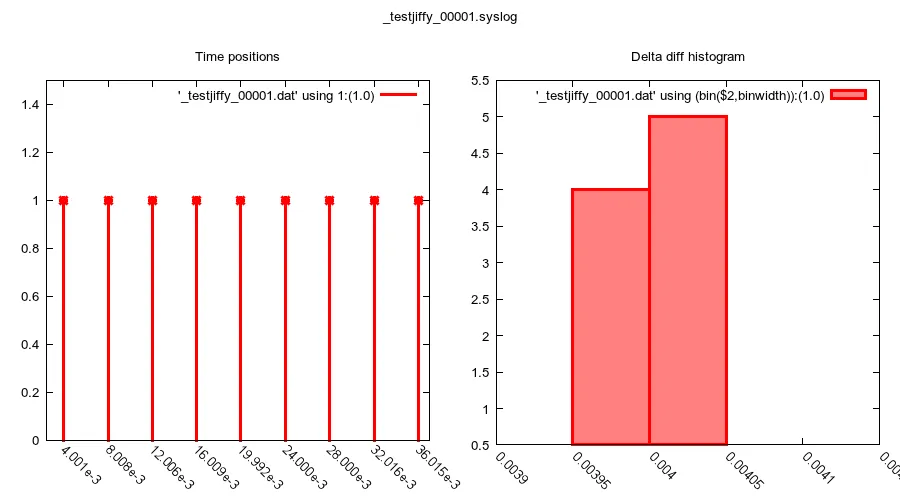
这基本上就是我从代码中期望得到的时间质量。
然而 - 偶尔,我会得到像这样的数据捕获:
[ 7121.377507] Init testjiffy: 0 ; HZ: 250 ; 1/HZ (ms): 4
[ 7121.380049] testjiffy_timer_function: runcount 1
[ 7121.384062] testjiffy_timer_function: runcount 2
[ 7121.392053] testjiffy_timer_function: runcount 3
[ 7121.396055] testjiffy_timer_function: runcount 4
[ 7121.400068] testjiffy_timer_function: runcount 5
[ 7121.404085] testjiffy_timer_function: runcount 6
[ 7121.408084] testjiffy_timer_function: runcount 7
[ 7121.412072] testjiffy_timer_function: runcount 8
[ 7121.416083] testjiffy_timer_function: runcount 9
[ 7121.420066] testjiffy_timer_function: runcount 10
[ 7122.417325] Exit testjiffy
... 这会导致呈现如下:
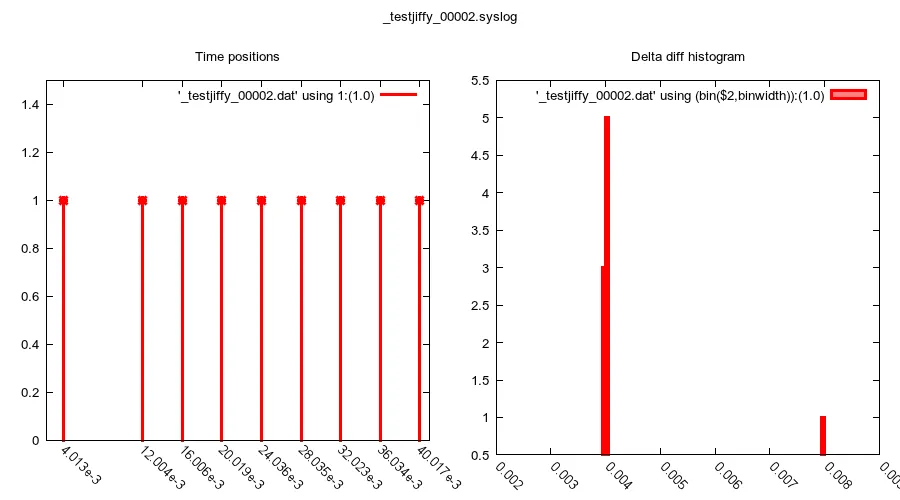
... 我就像:“哇啊啊啊啊啊……等一下……” - 序列中是否有一个脉冲被省略了?这意味着add_timer 漏掉了一个插槽,然后在下一个4毫秒插槽中启动了该函数?
有趣的是,在运行这些测试时,我只打开了终端、网络浏览器和文本编辑器 - 所以我无法看到任何可能占用操作系统/内核的运行情况;因此,我真的看不出内核为什么会出现如此大的误差(整个嘀嗒周期)。当我阅读有关Linux内核时间的文献时,例如“所有定时器中最简单且最不准确的是定时器API”,我把“最不准确”理解为:“不要期望 完全 的4毫秒周期”(根据此示例)- 我也不期望如此,我对(第一个)直方图中显示的方差感到满意;但我不期望整个周期会被省略!?
因此,我的问题是:
add_timer在这个分辨率下的表现是否符合预期(偶尔会漏掉一个周期)?- 如果是,有没有一种方法可以“强制”
add_timer在这个平台上按照每个4ms插槽指定的方式触发函数? - 是否可能会获得“错误”的时间戳 - 例如反映实际“打印”到系统日志发生的时间戳,而不是函数实际触发的时间戳?
- 请注意,我不希望超过对应于嘀嗒的周期分辨率(在本例中为4ms);也不希望在代码正常工作时减少增量方差。因此,在我看来,我没有“高分辨率计时器”需求,也没有“硬实时”需求 - 我只想让
add_timer可靠地触发。在这种平台上是否可能实现,而无需诉诸内核的特殊“实时”配置?
附加问题:在下面的rerun.sh中,您会注意到两个标有MUSTHAVE的sleep;如果其中任何一个被忽略/注释掉,操作系统/内核就会冻结,并需要进行硬重启。我看不出原因 - 真的可能在从bash中运行rmmod后进行insmod是如此快,以至于它会与模块加载/卸载的正常过程发生冲突吗?
平台信息:
$ cat /proc/cpuinfo | grep "processor\|model name\|MHz\|cores"
processor : 0 # (same for 1)
model name : Intel(R) Atom(TM) CPU N450 @ 1.66GHz
cpu MHz : 1000.000
cpu cores : 1
$ echo $(cat /etc/issue ; uname -a)
Ubuntu 11.04 \n \l Linux mypc 2.6.38-16-generic #67-Ubuntu SMP Thu Sep 6 18:00:43 UTC 2012 i686 i686 i386 GNU/Linux
$ echo $(lsb_release -a 2>/dev/null | tr '\n' ' ')
Distributor ID: Ubuntu Description: Ubuntu 11.04 Release: 11.04 Codename: natty
代码:
$ cd /tmp/testjiffy
$ ls
Makefile rerun.sh testjiffy.c
Makefile:
obj-m += testjiffy.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
testjiffy.c:
/*
* [http://www.tldp.org/LDP/lkmpg/2.6/html/lkmpg.html#AEN189 The Linux Kernel Module Programming Guide]
*/
#include <linux/module.h> /* Needed by all modules */
#include <linux/kernel.h> /* Needed for KERN_INFO */
#include <linux/init.h> /* Needed for the macros */
#include <linux/jiffies.h>
#include <linux/time.h>
#define MAXRUNS 10
static volatile int runcount = 0;
static struct timer_list my_timer;
static void testjiffy_timer_function(unsigned long data)
{
int tdelay = 100;
runcount++;
if (runcount == 5) {
while (tdelay > 0) { tdelay--; } // small delay
}
printk(KERN_INFO
" %s: runcount %d \n",
__func__, runcount);
if (runcount < MAXRUNS) {
my_timer.expires = jiffies + 1;
add_timer(&my_timer);
}
}
static int __init testjiffy_init(void)
{
printk(KERN_INFO
"Init testjiffy: %d ; HZ: %d ; 1/HZ (ms): %d\n",
runcount, HZ, 1000/HZ);
init_timer(&my_timer);
my_timer.function = testjiffy_timer_function;
//my_timer.data = (unsigned long) runcount;
my_timer.expires = jiffies + 1;
add_timer(&my_timer);
return 0;
}
static void __exit testjiffy_exit(void)
{
printk(KERN_INFO "Exit testjiffy\n");
}
module_init(testjiffy_init);
module_exit(testjiffy_exit);
MODULE_LICENSE("GPL");
rerun.sh:
#!/usr/bin/env bash
set -x
make clean
make
# blank syslog first
sudo bash -c 'echo "0" > /var/log/syslog'
sleep 1 # MUSTHAVE 01!
# reload kernel module/driver
sudo insmod ./testjiffy.ko
sleep 1 # MUSTHAVE 02!
sudo rmmod testjiffy
set +x
# copy & process syslog
max=0;
for ix in _testjiffy_*.syslog; do
aa=${ix#_testjiffy_};
ab=${aa%.syslog} ;
case $ab in
*[!0-9]*) ab=0;; # reset if non-digit obtained; else
*) ab=$(echo $ab | bc);; # remove leading zeroes (else octal)
esac
if (( $ab > $max )) ; then
max=$((ab));
fi;
done;
newm=$( printf "%05d" $(($max+1)) );
PLPROC='chomp $_;
if (!$p) {$p=0;}; if (!$f) {$f=$_;} else {
$a=$_-$f; $d=$a-$p;
print "$a $d\n" ; $p=$a;
};'
set -x
grep "testjiffy" /var/log/syslog | cut -d' ' -f7- > _testjiffy_${newm}.syslog
grep "testjiffy_timer_function" _testjiffy_${newm}.syslog \
| sed 's/\[\(.*\)\].*/\1/' \
| perl -ne "$PLPROC" \
> _testjiffy_${newm}.dat
set +x
cat > _testjiffy_${newm}.gp <<EOF
set terminal pngcairo font 'Arial,10' size 900,500
set output '_testjiffy_${newm}.png'
set style line 1 linetype 1 linewidth 3 pointtype 3 linecolor rgb "red"
set multiplot layout 1,2 title "_testjiffy_${newm}.syslog"
set xtics rotate by -45
set title "Time positions"
set yrange [0:1.5]
set offsets graph 50e-3, 1e-3, 0, 0
plot '_testjiffy_${newm}.dat' using 1:(1.0):xtic(gprintf("%.3se%S",\$1)) notitle with points ls 1, '_testjiffy_${newm}.dat' using 1:(1.0) with impulses ls 1
binwidth=0.05e-3
set boxwidth binwidth
bin(x,width)=width*floor(x/width) + width/2.0
set title "Delta diff histogram"
set style fill solid 0.5
set autoscale xy
set offsets graph 0.1e-3, 0.1e-3, 0.1, 0.1
plot '_testjiffy_${newm}.dat' using (bin(\$2,binwidth)):(1.0) smooth freq with boxes ls 1
unset multiplot
EOF
set -x; gnuplot _testjiffy_${newm}.gp ; set +x
编辑:受@granquet的评论启发,我尝试使用dd通过call_usermodehelper从/proc/schedstat和/proc/sched_debug获取调度器统计信息;注意,大多数情况下会“跳过”(也就是说,由于函数的第7次、第6次或X次运行而导致文件丢失); 但我设法获得了两次完整的运行,并将它们发布在https://gist.github.com/anonymous/5709699上(因为我注意到在SO上可能更喜欢使用gist而不是pastebin),鉴于输出非常庞大; *_11*文件记录了一次正确的运行,*_17*文件记录了一次“丢失”的运行。
请注意,我还切换到模块中的mod_timer_pinned,但它并没有太大帮助(使用此函数的模块生成了gist日志)。这些是testjiffy.c中的更改:
#include <linux/kmod.h> // usermode-helper API
...
char fcmd[] = "of=/tmp/testjiffy_sched00";
char *dd1argv[] = { "/bin/dd", "if=/proc/schedstat", "oflag=append", "conv=notrunc", &fcmd[0], NULL };
char *dd2argv[] = { "/bin/dd", "if=/proc/sched_debug", "oflag=append", "conv=notrunc", &fcmd[0], NULL };
static char *envp[] = {
"HOME=/",
"TERM=linux",
"PATH=/sbin:/bin:/usr/sbin:/usr/bin", NULL };
static void testjiffy_timer_function(unsigned long data)
{
int tdelay = 100;
unsigned long tjnow;
runcount++;
if (runcount == 5) {
while (tdelay > 0) { tdelay--; } // small delay
}
printk(KERN_INFO
" %s: runcount %d \n",
__func__, runcount);
if (runcount < MAXRUNS) {
mod_timer_pinned(&my_timer, jiffies + 1);
tjnow = jiffies;
printk(KERN_INFO
" testjiffy expires: %lu - jiffies %lu => %lu / %lu\n",
my_timer.expires, tjnow, my_timer.expires-tjnow, jiffies);
sprintf(fcmd, "of=/tmp/testjiffy_sched%02d", runcount);
call_usermodehelper( dd1argv[0], dd1argv, envp, UMH_NO_WAIT );
call_usermodehelper( dd2argv[0], dd2argv, envp, UMH_NO_WAIT );
}
}
...并且在rerun.sh中也有这个操作:
...
set +x
for ix in /tmp/testjiffy_sched*; do
echo $ix | tee -a _testjiffy_${newm}.sched
cat $ix >> _testjiffy_${newm}.sched
done
set -x ; sudo rm /tmp/testjiffy_sched* ; set +x
cat > _testjiffy_${newm}.gp <<EOF
...
我将使用这篇文章进行详细回复。
@CL.: 非常感谢您的答案。很高兴得到确认,"可能会在后面的jiffy中调用定时器函数";通过记录时间片(jiffies),我也意识到定时器函数在稍晚的时间被调用 - 除此之外,并没有任何 "错误"。
了解时间戳(timestamps)是很好的事情;我想知道是否有可能:定时器函数在正确的时间触发,但内核抢占了内核日志服务(我相信它是klogd),所以我得到了延迟的时间戳?然而,我正在尝试创建一个"循环"(或者说周期性的)定时器函数来写入硬件,我首先通过意识到PC在USB总线上某些时间间隔不写数据来注意到这个"丢失",鉴于时间戳可以证实这种行为,这里可能不是问题(我猜测)。
我已经修改了定时器函数,使其相对于上一个定时器的计划时间(my_timer.expires)触发 - 再次通过mod_timer_pinned而不是add_timer:
static void testjiffy_timer_function(unsigned long data)
{
int tdelay = 100;
unsigned long tjlast;
unsigned long tjnow;
runcount++;
if (runcount == 5) {
while (tdelay > 0) { tdelay--; } // small delay
}
printk(KERN_INFO
" %s: runcount %d \n",
__func__, runcount);
if (runcount < MAXRUNS) {
tjlast = my_timer.expires;
mod_timer_pinned(&my_timer, tjlast + 1);
tjnow = jiffies;
printk(KERN_INFO
" testjiffy expires: %lu - jiffies %lu => %lu / %lu last: %lu\n",
my_timer.expires, tjnow, my_timer.expires-tjnow, jiffies, tjlast);
}
}
......在前几次尝试中,它运行得非常完美——然而,最终,我会得到这个:
[13389.775508] Init testjiffy: 0 ; HZ: 250 ; 1/HZ (ms): 4
[13389.776051] testjiffy_timer_function: runcount 1
[13389.776063] testjiffy expires: 3272445 - jiffies 3272444 => 1 / 3272444 last: 3272444
[13389.780053] testjiffy_timer_function: runcount 2
[13389.780068] testjiffy expires: 3272446 - jiffies 3272445 => 1 / 3272445 last: 3272445
[13389.788054] testjiffy_timer_function: runcount 3
[13389.788073] testjiffy expires: 3272447 - jiffies 3272447 => 0 / 3272447 last: 3272446
[13389.788090] testjiffy_timer_function: runcount 4
[13389.788096] testjiffy expires: 3272448 - jiffies 3272447 => 1 / 3272447 last: 3272447
[13389.792070] testjiffy_timer_function: runcount 5
[13389.792091] testjiffy expires: 3272449 - jiffies 3272448 => 1 / 3272448 last: 3272448
[13389.796044] testjiffy_timer_function: runcount 6
[13389.796062] testjiffy expires: 3272450 - jiffies 3272449 => 1 / 3272449 last: 3272449
[13389.800053] testjiffy_timer_function: runcount 7
[13389.800063] testjiffy expires: 3272451 - jiffies 3272450 => 1 / 3272450 last: 3272450
[13389.804056] testjiffy_timer_function: runcount 8
[13389.804072] testjiffy expires: 3272452 - jiffies 3272451 => 1 / 3272451 last: 3272451
[13389.808045] testjiffy_timer_function: runcount 9
[13389.808057] testjiffy expires: 3272453 - jiffies 3272452 => 1 / 3272452 last: 3272452
[13389.812054] testjiffy_timer_function: runcount 10
[13390.815415] Exit testjiffy
...渲染如下:
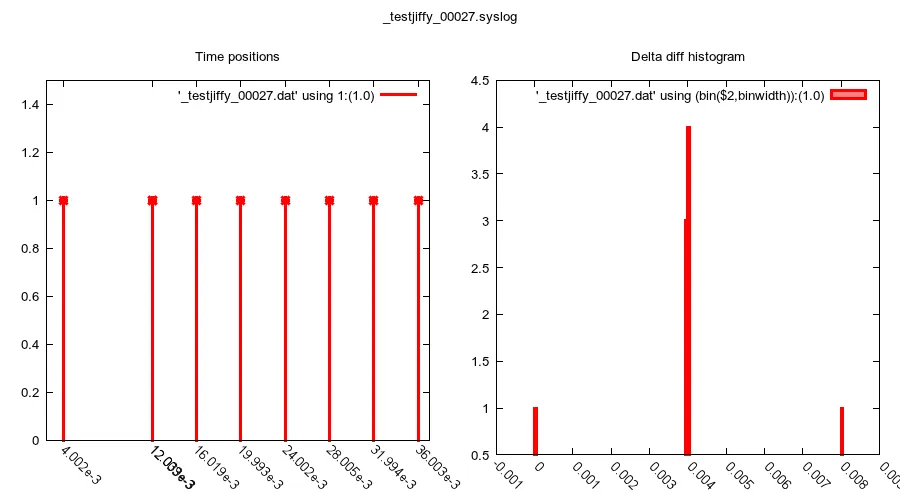
...所以,基本上我在+8毫秒时隔了一段时间 / “掉落”(应该是@3272446个jiffies),然后在+12毫秒时刻(应该是@3272447个jiffies)运行了两个函数;您甚至可以看到由于此原因,在绘图上的标签“更加粗体”。从这个意义上说,这更好,因为“掉落”序列现在与一个正确的、非丢失序列同步了(正如您所说:“为了避免一个延迟的计时器函数移动所有后续计时器调用”)。但是,我还是错过了节拍;而因为我需要在每个节拍上写入字节到硬件中,以保持持续的、恒定的传输速率,所以这对我帮助不大。
至于另一个建议,“使用十个计时器”——因为我的最终目标是(使用周期性低分辨率计时器函数写入硬件);我起初认为它不适用——但如果除了进行一些特殊的实时内核准备之外没有其他可能性,那么我肯定会尝试一种方案,即我有10(或N)个计时器(可能存储在一个数组中),它们依次周期性地触发。
编辑:只添加剩余的相关评论:
USB传输要么提前安排(等时的),要么没有时间保证(异步的)。如果您的设备不使用等时传输,则设计有误。 – CL. 6月5日10:47
感谢您的评论,@CL.——“…提前安排(等时)…”消除了我所拥有的困惑。我最终的目标是针对FT232,它只有BULK模式-只要每个计时器命中的字节数较低,我实际上可以通过add_timer“欺骗”我的方式在“流式传输”中传递数据;然而,当我传输接近消耗带宽的字节数时,这些“误火”开始变得明显起来。因此,我对测试其极限很感兴趣,为此我需要一个可靠的重复“计时器”函数-还有其他任何我可以尝试以获得可靠“计时器”的方法吗? –sdaau 6月5日12:27
@sdaau,大容量传输不适用于流媒体。你不能通过使用另一种软件定时器来解决硬件协议中的缺陷。– CL. 6月5日13:50
...而作为我对@CL的回应:我知道我无法修复缺陷;我更感兴趣的是观察这些缺陷--比如,如果一个内核函数进行周期性的USB写操作,我可以在示波器/分析仪上观察信号,并希望看到何种意义上块模式不适用。但首先,我必须相信这个函数能够(至少有点)可靠地以周期性的速率重复执行(即“生成”时钟/节拍)-而直到现在,我并不知道我不能真正相信add_timer以jiffies分辨率(因为它很容易跳过整个周期)。然而,移动到Linux的高分辨率定时器(hrtimer)确实为我提供了一个可靠的周期函数,在这个意义上解决了我的问题(在我下面的答案中发布)。
/proc/schedstat和/proc/sched_debug中读取,并在两种情况下收集它;请参见编辑结束的原始帖子,其中包含日志链接。这是你所说的打印“调度器统计信息”吗?我能找到的少数几个相关链接是sched-stats.txt 和 Linux Scheduler Statistics;然后,我最好读取/proc。干杯! - sdaau