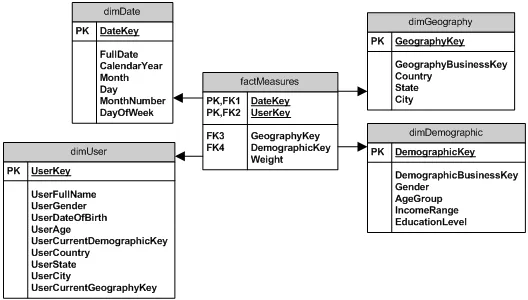
我正在使用关系型数据库构建一个简易的数据仓库。我已确定需要记录以下关键“属性”:
- 性别(真/假)
- 人口统计分类(A,B,C等)
- 出生地点
- 出生日期
- 体重(每天记录):所记录的事实
我的要求是能够运行允许我执行“OLAP”查询的查询,这些查询使我能够:
- “切片和切块”
- 在数据上“钻取”
- 一般地,能够从不同的角度查看数据
阅读了这个主题领域后,普遍的共识似乎是最好使用维度表来实现这一目标,而不是规范化的表。
假设这种说法是正确的(即解决方案最好使用事实和维度表实现),我想在这些表的设计中寻求一些帮助。
“自然”(或明显)的维度包括:
- 日期维度
- 地理位置
这些维度具有分层属性。然而,我在如何对以下字段进行建模时遇到了困难:
- 性别(真/假)
- 人口统计分类(A,B,C等)
我在这些字段上的困惑是:
- 它们没有明显的分层属性可以帮助聚合(据我所知),这表明它们应该在事实表中。
- 它们大多是静态或很少改变的 - 这表明它们应该在维度表中。
也许我使用的启发式方法太粗糙了?
我将举一些关于我希望在数据仓库中进行的分析类型的例子 - 希望这些例子能进一步澄清问题。
我想通过性别和人口统计分类聚合和分析数据 - 例如回答以下问题:
- 不同人口统计分类下男女的体重如何比较?
- 哪种人口统计分类(男性和女性)显示本季度最大的增长?
等等。
有人能否澄清性别和人口统计分类是否属于事实表,还是像我怀疑的那样属于维度表?
并且假设它们是维度表,有人可以详细说明表结构(即字段)吗?
“明显”的模式:
CREATE TABLE sex_type (is_male int);
CREATE TABLE demographic_category (id int, name varchar(4));
可能不是正确的。