您好,我正在为自己的数据集训练VGG16网络。以下是我使用的代码。
from keras.models import Sequential
from scipy.misc import imread
#get_ipython().magic('matplotlib inline')
import matplotlib.pyplot as plt
import numpy as np
import keras
from keras.layers import Dense
import pandas as pd
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input
import numpy as np
from keras.applications.vgg16 import decode_predictions
from keras.utils.np_utils import to_categorical
from sklearn.preprocessing import LabelEncoder
from keras.models import Sequential
from keras.optimizers import SGD
from keras.layers import Input, Dense, Convolution2D, MaxPooling2D, AveragePooling2D, ZeroPadding2D, Dropout, Flatten, merge, Reshape, Activation
import os
from sklearn.metrics import log_loss
import cv2
from keras.models import Model
from sklearn import cross_validation
from imagenet_utils import preprocess_input
from imagenet_utils import preprocess_input,decode_predictions
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session
from skimage import measure, morphology
from mpl_toolkits.mplot3d.art3d import Poly3DCollection
from os import walk
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import confusion_matrix
os.environ['CUDA_VISIBLE_DEVICES'] = '-1'
def load_images():
def train_test_separation():
df = pd.read_csv('C:/CT_SCAN_IMAGE_SET/resnet_50/dbs2017/data/stage1_labels.csv')
print(df.head())
#print (filenames,' ',pathname,' ',BASE_PATH )
#images=load_images()
labeling = df['cancer'].as_matrix()
names=['Not_Cancer','Cancer']
Y_category=keras.utils.to_categorical(labeling, num_classes=2)
x = np.array([np.mean(np.load('E:/224x224/%s.npy' % str(id)), axis=0) for id in df['id'].tolist()])
print ('.......................................',Y_category.shape)
img_rows, img_cols = 224, 224 # Resolution of inputs
channel = 3
num_classes = 2
batch_size = 50
nb_epoch = 1
# Load Cifar10 data. Please implement your own load_data() module for your own dataset
X_train, Y_train, X_valid, Y_valid = cross_validation.train_test_split(x, Y_category, random_state=42, test_size=0.20)
print (X_train.shape) #(1107, 3, 224, 224)
print (Y_train.shape) #(277, 3, 224, 224)
print (X_valid.shape) #(1107, 2)
print (Y_valid.shape) #(277, 2)
X_train = X_train.transpose(0,2,3,1)
Y_train = Y_train.transpose(0,2,3,1)
print (X_train.shape) # (1107, 224, 224, 3)
# Load our model
# Load our model
model = vgg16_model(img_rows, img_cols, channel, num_classes)
print ('.........................................',Y_valid.shape) #(277, 2)
model.summary()
# Start Fine-tuning and training
#config = tf.ConfigProto(log_device_placement=False, allow_soft_placement=True)
#config.gpu_options.allow_growth=True
#config.gpu_options.per_process_gpu_memory_fraction = 0.95
#set_session(tf.Session(config=config))
hist=model.fit(X_train, X_valid,batch_size=batch_size,epochs=nb_epoch,shuffle=True,verbose=1,validation_data=(Y_train, Y_valid))
#validation_data: tuple (x_val, y_val) or tuple (x_val, y_val, val_sample_weights) on which to evaluate the loss and any model
#metrics at the end of each epoch. The model will not be trained on this data. This will override validation_split
(loss,accuracy)=model.evaluate(Y_train,Y_valid,batch_size=batch_size,verbose=1)
print ("[INFO] loss={:.4f},accuracy: {:.4f}%".format(loss,accuracy*100))
df = pd.read_csv('C:/CT_SCAN_IMAGE_SET/resnet_50/dbs2017/data/stage1_sample_submission.csv')
df2 = pd.read_csv('C:/CT_SCAN_IMAGE_SET/resnet_50/dbs2017/data/stage1_solution.csv')
x = np.array([np.mean(np.load('E:/224x224/%s.npy' % str(id)), axis=0) for id in df['id'].tolist()])
x = x.transpose(0,2,3,1)
# Make predictions
pred = model.predict(x, batch_size=batch_size, verbose=1) #predict(self, x, batch_size=None, verbose=0, steps=None)
print (pred)
# Cross-entropy loss score
score = log_loss(x, predictions_valid)
def vgg16_model(img_rows, img_cols, channel=1, num_classes=None):
print ('aaaaaaaaaaaaaaaaaa')
image_input=Input(shape=(224,224,3))
model = VGG16(weights='imagenet', include_top=True, input_tensor=image_input)
print ('bbbbbbbbbbbbbbbbbbbbb')
model.summary()
last_layer=model.get_layer('fc2').output # last layer which will be 4096
# Will add one layer over it.
out=Dense(num_classes, activation='softmax',name='output')(last_layer)
custom_vgg_model=Model(image_input,out) #Creating the custom model using the Keras, Modelfunction.
custom_vgg_model.summary()
#Now you can train the model. Before that you need to compile it.
custom_vgg_model.compile(loss='categorical_crossentropy',optimizer='adadelta',metrics=['accuracy'])
#We do not need to train the etire network. Instead we need to train the last layer.
#All the layers except thelast layer will be freezed
for layer in custom_vgg_model.layers[:-1]:
layer.trainable=False
custom_vgg_model.layers[3].trainable
return custom_vgg_model
if __name__ == '__main__':
#calc_features()
train_test_separation()
但是在训练过程中,我发现了一些异常情况。我的数据集没有得到训练。我只改变了softmax分类器层并冻结了上面的所有其他层。在此之后显示模型摘要时,我收到了一个用户警告,如标题所示。
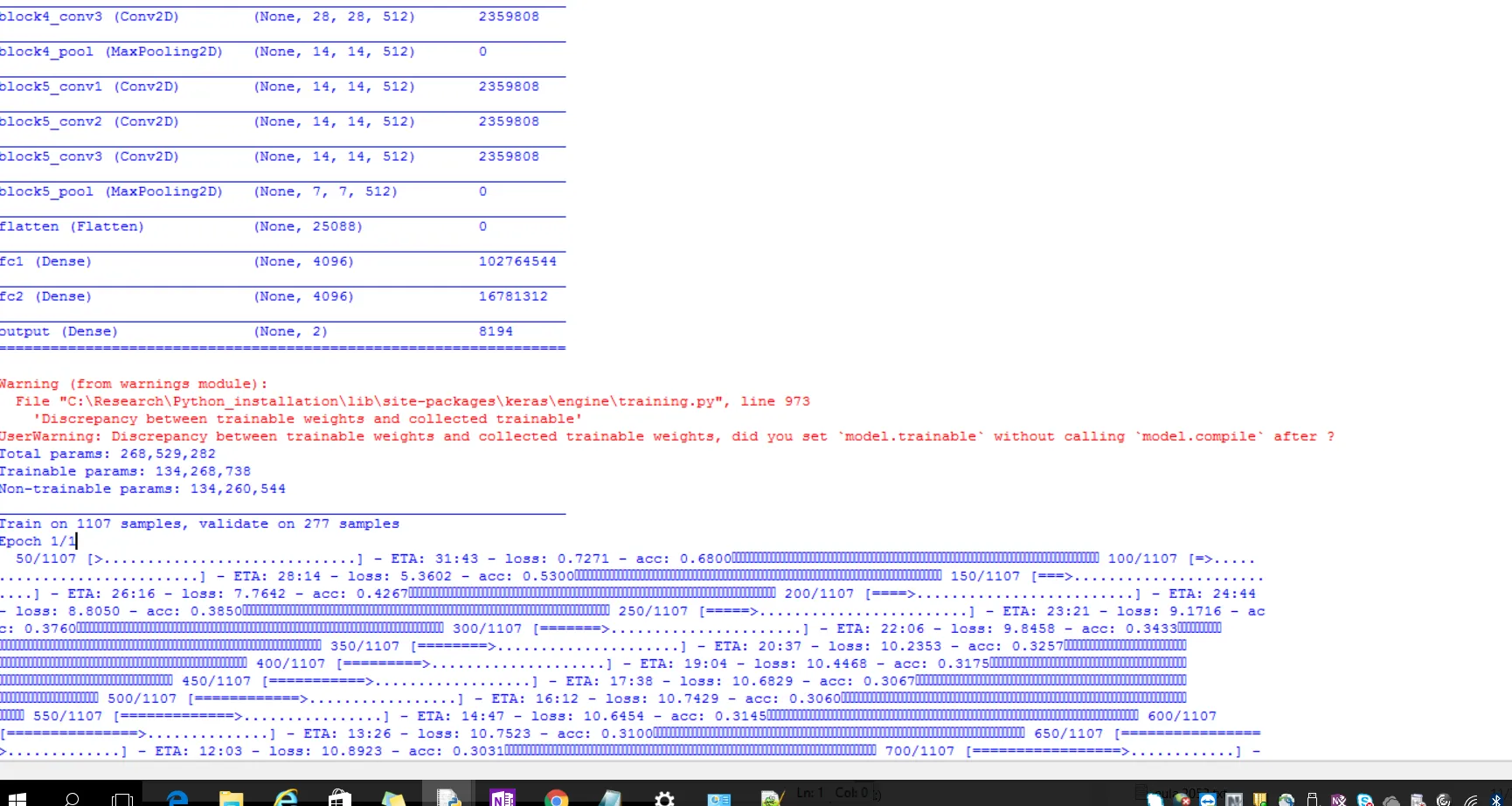
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
output (Dense) (None, 2) 8194
=================================================================
Warning (from warnings module):
File "C:\Research\Python_installation\lib\site-packages\keras\engine\training.py", line 973
'Discrepancy between trainable weights and collected trainable'
UserWarning: Discrepancy between trainable weights and collected trainable weights, did you set `model.trainable` without calling `model.compile` after ?
Total params: 268,529,282
Trainable params: 134,268,738
Non-trainable params: 134,260,544
_________________________________________________________________
Train on 1107 samples, validate on 277 samples
Epoch 1/1
50/1107 [>.............................] - ETA: 31:43 - loss: 0.7271 - acc: 0.6800������������������������������������������������������������������������������������
100/1107 [=>............................] - ETA: 28:14 - loss: 5.3602 - acc: 0.5300������������������������������������������������������������������������������������
150/1107 [===>..........................] - ETA: 26:16 - loss: 7.7642 - acc: 0.4267������������������������������������������������������������������������������������
200/1107 [====>.........................] - ETA: 24:44 - loss: 8.8050 - acc: 0.3850������������������������������������������������������������������������������������
250/1107 [=====>........................] - ETA: 23:21 - loss: 9.1716 - acc: 0.3760������������������������������������������������������������������������������������
300/1107 [=======>......................] - ETA: 22:06 - loss: 9.8458 - acc: 0.3433������������������������������������������������������������������������������������
350/1107 [========>.....................] - ETA: 20:37 - loss: 10.2353 - acc: 0.3257�������������������������������������������������������������������������������������
400/1107 [=========>....................] - ETA: 19:04 - loss: 10.4468 - acc: 0.3175�������������������������������������������������������������������������������������
450/1107 [===========>..................] - ETA: 17:38 - loss: 10.6829 - acc: 0.3067�������������������������������������������������������������������������������������
500/1107 [============>.................] - ETA: 16:12 - loss: 10.7429 - acc: 0.3060������������������������������������������
如果模型运行良好,则
Non-trainable params: 134,260,544
计数不应该是134,260,544,而应该是8194。但我收到了用户警告,计数却变成了134,260,544,而非8194。
当显示经过验证的数据集的预测输出时,结果如下所示。
[[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
这意味着数据集并没有被正确分类。请有人能够帮我找出我的错误吗?我收到了一个用户警告。
Warning (from warnings module):
File "C:\Research\Python_installation\lib\site-packages\keras\engine\training.py", line 973
'Discrepancy between trainable weights and collected trainable'
UserWarning: Discrepancy between trainable weights and collected trainable weights, did you set `model.trainable` without calling `model.compile` after ?
discriminator.trainable=False并创建一个组合的生成器+鉴别器模型,我仍然会收到这个警告。我可以忽略这个警告,对吗?因为我认为我的模型的计算图是正确的。 - Harshit Trehan