我需要比较两个日志文件,但忽略每行的时间戳部分(确切地说是前12个字符)。是否有一个好的工具或聪明的awk命令可以帮助我完成?
6个回答
26
@EbGreen说:
我会提取日志文件并剥离每行开头的时间戳,然后将文件保存到不同的文件中。 然后比较这些文件。
那可能是最好的选择,除非您的比较工具有特殊功能。例如,您可以
cut -b13- file1 > trimmed_file1
cut -b13- file2 > trimmed_file2
diff trimmed_file1 trimmed_file2
如您的 shell 支持,可以查看 @toolkit 的答复以获得一行代码的优化解决方案,并避免使用额外的文件。至少可以在 Bash 3.2.39 中实现...
- Blair Conrad
1
如果某人的时间戳也有ISO格式的日期,则使用-b25-。 - Brian B
20
使用 cut 命令回答是可以的,但有时在 diff 输出中保留时间戳是可取的。由于提问者的问题是关于忽略时间戳(而不是删除它们),我在此分享我的巧妙命令行:
diff -I '^#' <(sed -r 's/^((.){12})/#\1\n/' 1.log) <(sed -r 's/^((.){12})/#\1\n/' 2.log)
sed通过进程替换,隔离出时间戳(指位于#之前以及\n之后)。diff -I '^#'忽略掉包含这些时间戳的行(以#开头的行)。
示例
两个日志文件内容相同但时间戳不同:
$> for ((i=1;i<11;i++)) do echo "09:0${i::1}:00.000 data $i"; done > 1.log
$> for ((i=1;i<11;i++)) do echo "11:00:0${i::1}.000 data $i"; done > 2.log
基本的diff命令行显示所有行都不同:
$> diff 1.log 2.log
1,10c1,10
< 09:01:00.000 data 1
< 09:02:00.000 data 2
< 09:03:00.000 data 3
< 09:04:00.000 data 4
< 09:05:00.000 data 5
< 09:06:00.000 data 6
< 09:07:00.000 data 7
< 09:08:00.000 data 8
< 09:09:00.000 data 9
< 09:01:00.000 data 10
---
> 11:00:01.000 data 1
> 11:00:02.000 data 2
> 11:00:03.000 data 3
> 11:00:04.000 data 4
> 11:00:05.000 data 5
> 11:00:06.000 data 6
> 11:00:07.000 data 7
> 11:00:08.000 data 8
> 11:00:09.000 data 9
> 11:00:01.000 data 10
我们这个棘手的
diff -I '^#' 命令不会显示任何差异(时间戳被忽略):$> diff -I '^#' <(sed -r 's/^((.){12})/#\1\n/' 1.log) <(sed -r 's/^((.){12})/#\1\n/' 2.log)
$>
修改 2.log 文件(将第 6 行的 data 替换为 foo),然后再次检查:
$> sed '6s/data/foo/' -i 2.log
$> diff -I '^#' <(sed -r 's/^((.){12})/#\1\n/' 1.log) <(sed -r 's/^((.){12})/#\1\n/' 2.log)
11,13c11,13
11,13c11,13
< #09:06:00.000
< data 6
< #09:07:00.000
---
> #11:00:06.000
> foo 6
> #11:00:07.000
=> 时间戳被记录在diff输出中!
您还可以使用-y或--side-by-side选项来使用并排功能:
$> diff -y -I '^#' <(sed -r 's/^((.){12})/#\1\n/' 1.log) <(sed -r 's/^((.){12})/#\1\n/' 2.log)
#09:01:00.000 #11:00:01.000
data 1 data 1
#09:02:00.000 #11:00:02.000
data 2 data 2
#09:03:00.000 #11:00:03.000
data 3 data 3
#09:04:00.000 #11:00:04.000
data 4 data 4
#09:05:00.000 #11:00:05.000
data 5 data 5
#09:06:00.000 | #11:00:06.000
data 6 | foo 6
#09:07:00.000 | #11:00:07.000
data 7 data 7
#09:08:00.000 #11:00:08.000
data 8 data 8
#09:09:00.000 #11:00:09.000
data 9 data 9
#09:01:00.000 #11:00:01.000
data 10 data 10
旧版的 sed
如果你的 sed 实现不支持 -r 选项,那么你可能需要计算十二个点号 <(sed 's/^\(............\)/#\1\n/' 1.log) 或者使用其他模式 ;)
- oHo
2
2感谢您的巧妙解决方案,这让我省去了数小时尝试在awk中完成此操作的时间(而且我可能需要切换到perl来保持理智)。 - ack
是的!这是一个很棒的解决方案!这个问题经常出现,meld是为数不多的可以做到这一点的工具之一,而且只使用标准工具就能够提供一个命令行解决方案,真是太好了! - Matt Hellige
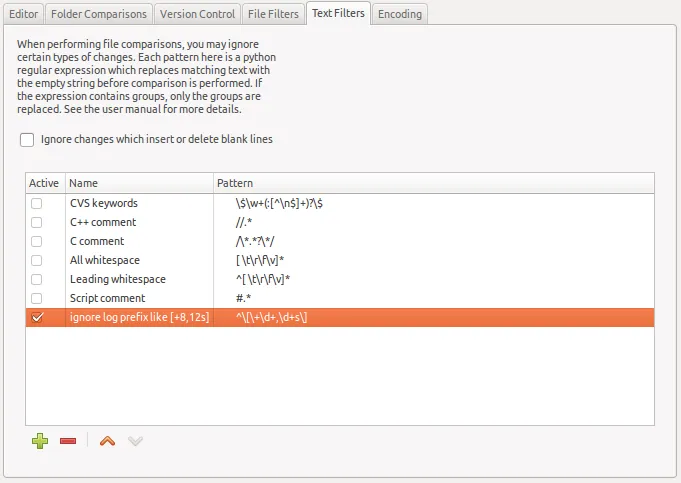
3
请使用Kdiff3。在配置>比较中编辑"行匹配预处理器命令"为以下内容:
sed "s/[ 012][0-9]:[0-5][0-9]:[0-5][0-9]//"
这将从比对对齐算法中过滤出时间戳。
Kdiff3还允许您手动对齐特定行。
- Pedro Reis
2
1文件在每一行仍然被标记为不同,但它允许我使用命令“转到下一个/上一个差异”搜索真正的差异。 - Melebius
并且可以直接从命令行执行:
kdiff3 --cs LineMatchingPreProcessorCmd="sed \"s/[ 012][0-9]:[0-5][0-9]:[0-5][0-9]//\"" "/path/to/file 1.txt" "/path/to/file 2.txt" - Colin1
我想提出一个Visual Studio Code的解决方案:
- 安装这个扩展 - https://marketplace.visualstudio.com/items?itemName=ryu1kn.partial-diff
- 按照这个配置 - https://github.com/ryu1kn/vscode-partial-diff/issues/49#issuecomment-608299085 进行设置
- 运行扩展命令“切换预比较文本规则”,并启用第2步添加的规则
- 使用该扩展(这里有一个UI怪异的解释 - https://github.com/ryu1kn/vscode-partial-diff/issues/11)
- vlad2135
1
1不错的扩展!不幸的是,显示的差异显示了规范化文本(通过规范化规则进行替换的结果),而不是显示原始文本(仅为了生成差异突出显示而忽略部分内容)。相比之下,Meld的文本过滤器仅用于生成差异。 - sls
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
diff dir1 dir2,文件名称会被包括在内)。为什么会这样?这个问题能修复吗? - d-b