这些术语在我的数据结构教材中使用,但解释很简略且不清楚。我认为它与算法每个计算阶段拥有多少知识有关。
(请不要链接到维基百科页面:我已经阅读过它,仍然在寻找澄清。以十二岁的方式解释和/或提供示例会更有帮助。)
这些术语在我的数据结构教材中使用,但解释很简略且不清楚。我认为它与算法每个计算阶段拥有多少知识有关。
(请不要链接到维基百科页面:我已经阅读过它,仍然在寻找澄清。以十二岁的方式解释和/或提供示例会更有帮助。)
维基百科页面很清楚:
在计算机科学中,在线算法是一种可以按顺序逐个处理输入的算法,即按照输入到算法的顺序进行处理,而不需要从一开始就拥有整个输入。相比之下,离线算法从一开始就给出了所有问题数据,并要求输出解决该问题的答案。(例如,选择排序需要在对其进行排序之前提供整个列表,而插入排序则不需要。)
让我对上述内容进行扩展:
离线算法需要在算法开始之前获得所有信息。在维基百科的例子中,selection sort 是 离线 的,因为第一步是 查找列表中的最小值。为了做到这一点,你需要拥有整个列表 - 否则,你怎么可能知道最小值是什么呢? 你不可能知道。
相比之下,插入排序是在线排序的,因为它不需要知道要排序的值的任何信息,并且在算法运行时请求信息。简而言之,它可以在每次迭代时抓取新值。
想象一下以下例子(适用于四岁儿童!)。大卫要求您解决两个问题。
在第一个问题中,他说:
“我会给你两个具有不同质量的球,你需要从一个塔上同时将它们扔下来..只是为了确保伽利略是对的。你不能使用手表,我们只能凭眼观察。”
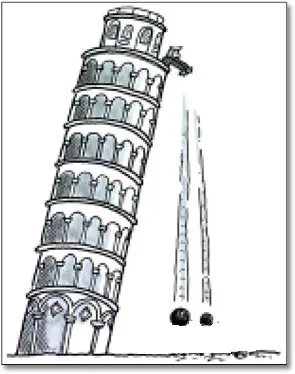

我先给你一颗球,你踢它。然后我再给你第二颗球,你也踢它。我甚至可以给你第三颗、第四颗球(而你甚至不知道我会给你这些球)。这就是一个在线算法的例子。事实上,你可以整天踢球。
希望这很清楚 :D
一遍算法是一种流式算法,它仅按顺序读取其输入,而不进行无限制的缓冲。一遍算法通常需要O(n)(参见“大O”符号)时间和少于O(n)(通常为O(1))的存储空间,其中n是输入的大小。在线算法是否是一遍算法的子集,其中算法的时间复杂度为O(n),其存储复杂度为O(1)?也就是说,对于给定的任务,在线算法是否是最有效的一遍算法?谢谢! - tonix离线算法在调用时就已经知道所有的输入数据。而在线算法则可能在运行过程中获取部分或全部的输入数据。
如果算法在执行之前不知道它将要处理的数据,则称其为在线算法。离线算法可以提前查看所有数据。