首先,我们知道二叉搜索树的搜索算法如下:
// Function to check if given key exists in given BST.
bool search (node* root, int key)
{
if (root == NULL)
return false;
if (root->key == key)
return true;
if (root->key > key)
return search(root->left, key);
else
return search(root->right, key);
}
这种搜索算法通常应用于二叉搜索树,但是对于一般的二叉树,这种算法可能会给我们带来错误的结果。
下面的问题让我困扰了很长时间。
给定一棵一般的二叉树,使用上述BST搜索算法可以找到其中多少个节点?
以下面的二叉树为例。可搜索的节点已用颜色标出,因此答案为3。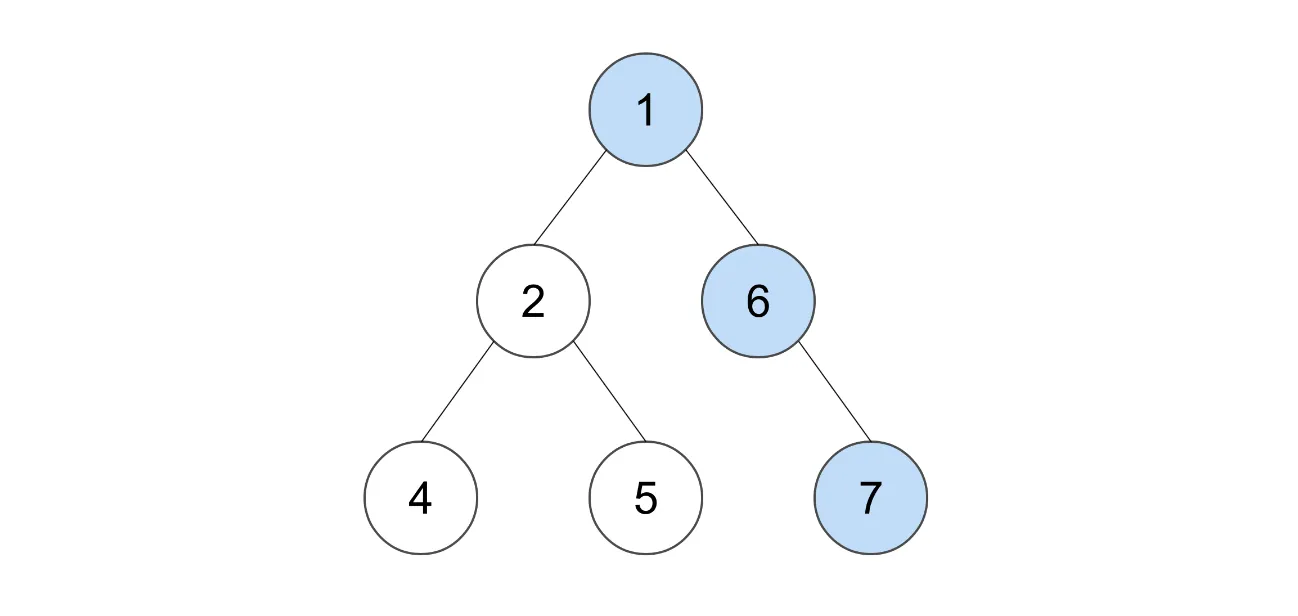
假设树中的键是唯一的,并且我们知道所有键的值。
我的想法
我有一个天真的解决方案,就是针对每个可能的键调用搜索算法,并计算函数返回true的次数。
然而,我想减少调用函数的次数,并改进时间复杂度。我的直觉告诉我,递归可能很有用,但我不确定。
我认为对于每个节点,我们需要其父节点(或祖先)的信息,因此我考虑定义如下的二叉树数据结构:
struct node {
int key;
struct node* left;
struct node* right;
struct node* parent; // Adding a 'parent' pointer may be useful....
};
我真的找不出一种有效的方法来判断一个节点是否可搜索,也找不到一种方法来找出可搜索节点的数量。因此,我来这里寻求帮助。提示比完整的解决方案更好。
这是我第一次在Stack Overflow上提问。如果您认为这篇文章需要改进,请随时留下评论。谢谢阅读。