(编辑)
该问题的渐进理论最佳方法是使用优先队列,例如在heapq.merge()中实现的方法(感谢@kaya3指出)。
然而,在实践中,很多事情可能会出错。例如,复杂度分析中的常数因子足够大,以至于理论上最优的方法在现实场景中更慢。
这基本上取决于实现方式。
例如,Python在显式循环方面会受到一些速度惩罚。
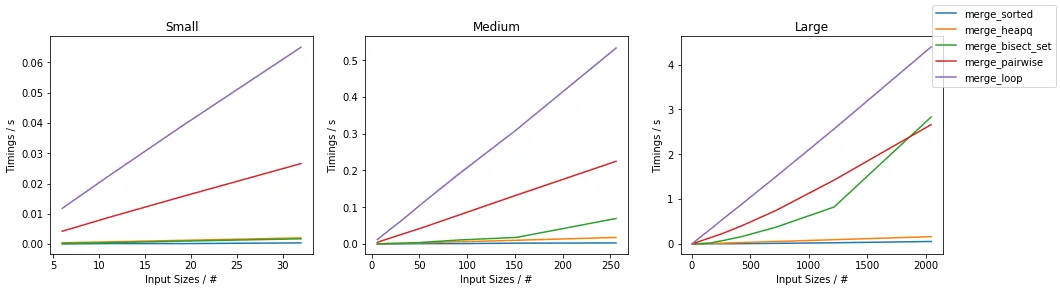
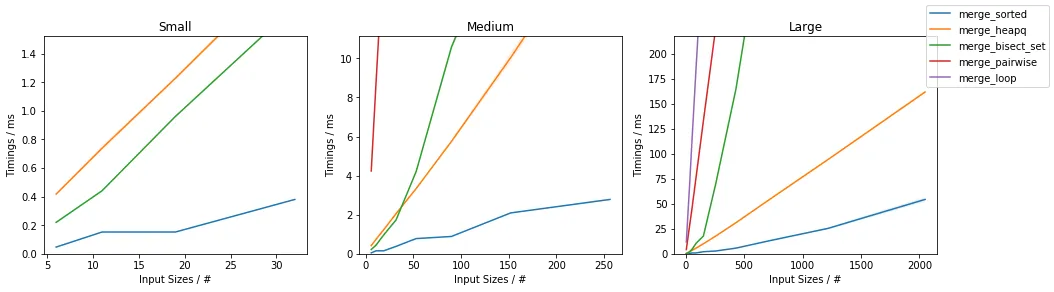
因此,让我们考虑几种方法以及它们在某些具体输入下的表现。
方法
为了给您一些我们正在讨论的数字的概念,这里有一些方法:
merge_sorted()使用最简单的方法,即展平序列,将其缩减到一个set()(删除重复项),并按需排序
import itertools
def merge_sorted(seqs):
return sorted(set(itertools.chain.from_iterable(seqs)))
merge_heapq() 实际上是 @arshajii 的答案。请注意,itertools.groupby() 变体略微(不到 ~1%)更快。
import heapq
def i_merge_heapq(seqs):
last_item = None
for item in heapq.merge(*seqs):
if item != last_item:
yield item
last_item = item
def merge_heapq(seqs):
return list(i_merge_heapq(seqs))
merge_bisect_set()是与merge_sorted()基本相同的算法,只不过结果现在使用高效的bisect模块进行排序插入而显式构造。由于sorted()基本上在Python中循环执行相同的操作,因此这并不会更快。
import itertools
import bisect
def merge_bisect_set(seqs):
result = []
for item in set(itertools.chain.from_iterable(seqs)):
bisect.insort(result, item)
return result
merge_bisect_cond()类似于merge_bisect_set(),但现在使用最终的list明确执行非重复约束条件。然而,这比仅使用set()要昂贵得多(实际上它太慢了,被排除在图表之外)。
def merge_bisect_cond(seqs):
result = []
for item in itertools.chain.from_iterable(seqs):
if item not in result:
bisect.insort(result, item)
return result
merge_pairwise() 显式地实现了理论上高效的算法,类似于您在问题中概述的算法。
def join_sorted(seq1, seq2):
result = []
i = j = 0
len1, len2 = len(seq1), len(seq2)
while i < len1 and j < len2:
if seq1[i] < seq2[j]:
result.append(seq1[i])
i += 1
elif seq1[i] > seq2[j]:
result.append(seq2[j])
j += 1
else:
result.append(seq1[i])
i += 1
j += 1
if i < len1:
result.extend(seq1[i:])
elif j < len2:
result.extend(seq2[j:])
return result
def merge_pairwise(seqs):
result = []
for seq in seqs:
result = join_sorted(result, seq)
return result
merge_loop() 实现了上述方法的一般化,现在只需对所有序列执行一次 pass,而不是成对执行。
def merge_loop(seqs):
result = []
lengths = list(map(len, seqs))
idxs = [0] * len(seqs)
while any(idx < length for idx, length in zip(idxs, lengths)):
item = min(
seq[idx]
for idx, seq, length in zip(idxs, seqs, lengths) if idx < length)
result.append(item)
for i, (idx, seq, length) in enumerate(zip(idxs, seqs, lengths)):
if idx < length and seq[idx] == item:
idxs[i] += 1
return result
基准测试
通过使用以下方法生成输入:
def gen_input(n, m=100, a=None, b=None):
if a is None and b is None:
b = 2 * n * m
a = -b
return tuple(tuple(sorted(set(random.randint(int(a), int(b)) for _ in range(n)))) for __ in range(m))
对于不同的n(每个序列的大小)和m(序列的数量),以及a和b(生成的最小和最大数)的不同值,性能通常会有所变化。
为简洁起见,本答案未进行探索,但可以在此处进行尝试,其中还包括一些其他实现,尤其是使用Cython进行的一些试图加速,但只部分成功。
可以绘制不同n的时间:
{kind=link}