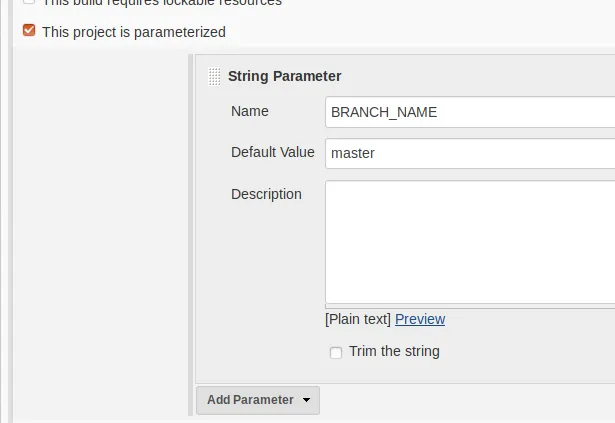
短而直接的答案是“不一定”。尽管Jenkins有一个复选框,但在这里使用它可能不是一个好主意——无论是否如此,取决于谁控制名称到ID映射。其他CI系统可能会有类似的复选框。要了解我在这里的意思,请继续阅读。
子模块的理念是超级项目控制其子模块。我认为,这部分对任何人来说既不令人惊讶也不可反对。但关键在于超级项目控制每个子模块的方式。这部分确实让人惊讶,原因相当简单。这是对Git存储库的基本误解。
人们认为,在Git存储库中重要的是“分支”,或更精确地说,分支名称,如“master”和“develop”。这根本不是真的。这些分支,在这里大部分是“几乎无关紧要”的。对于人类来说,这些分支名称具有巨大的、压倒性的目的。对于Git来说,它们提供了一个大多数是微不足道的点,同样适用于任何其他名称,例如标签名称、远程跟踪名称、“refs/stash”或“HEAD@{17}”。1
在Git中,
commit而不是分支名称(也不是标签名称或任何其他名称)是核心、必不可少的事情。Commits是Git的存在理由。没有commits,Git就没有功能。有了commits,Git才有用。实际上,commits通过它们的哈希ID进行识别,其真正的名称是那些像b5101f929789889c2e536d915698f58d5c5c6b7a这样的大丑字符串。像master或develop这样的
可读名称是为弱者、生物……人类而设的。
当然,我们作为软弱的人类,喜欢使用我们自己的名称。所以我们在我们的存储库中使用它们。但是当我们有一个控制另一个存储库(例如子模块)的超级项目这样的存储库时,在这种情况下,就没有人类参与。因此,Git使用提交ID来控制在每个子模块中提取哪个提交哈希ID。
所以这就是惊喜的地方 - 但是,一旦您理解Git来自哪里,这一点也不令人惊讶。当您让超级项目选择子模块提交时,超级项目通过哈希ID选择子模块提交。任何分支名称都无关紧要。哈希ID非常精确且始终正确。分支名称很随意-它们会随着时间的推移从提交到提交移动。一个提交哈希ID可以有零个或多个分支名称,这些分支名称直接指向它,或者可以通过提交图
2到达它。
您在超级项目中进行的每个提交都记录了预期子模块检出的确切子模块哈希ID。因此,当您在超级项目中
git checkout某个提交时,通常应立即让每个子模块通过超级项目中指定的哈希ID进行单独的
git checkout3。
请记住,每个子模块都是其自己的Git存储库,因此它具有自己的
HEAD、索引和工作树。子模块中的索引记录了检出到子模块的工作树中的文件,每个子模块中的
HEAD处于分离的HEAD模式下,记录当前检出提交的哈希ID。这是超级项目的Git通过将其存储在超级项目中的提交中选择的哈希ID,而子模块的Git有责任检出此特定提交。在此过程中没有提到分支名称。分支名称无关紧要!
1除了为弱势人类提供支撑外,名称的in-Git功能是保护对象免受“垃圾回收”的影响。如果一个对象从某个名称处无法访问,则它容易被回收。由于大多数提交通常是链接在一起的,因此一个名称往往会保护存储库中的大部分提交。有关详细信息,请参见脚注2。
2有关可达性的更多信息,请参见像Git一样思考。
3默认情况下,这并不会自动发生。您必须使用git checkout --recurse-submodules或在配置中设置submodule.recurse。根据您的操作方式(特别是如果您正在尝试更新子模块),自动发生可能非常方便,也可能非常烦人。
那么,为什么可以设置分支名称呢?
正如您所指出的,.gitmodules文件可以记录分支名称。 您还可以将其复制到.git/config中(如果两者都设置了,则.git/config设置会覆盖.gitmodules设置)。 但通常,子模块根本没有分支; 它被放置在脱离HEAD模式下,如上所述。 那么这个分支名称有什么好处呢?
第一个但有些不令人满意的答案是:它根本没有好处。 大多数操作都不使用它。
第二个更令人满意的答案是:一些特殊目的的操作会使用它。 具体而言,如果您正在更新超级项目,并希望创建一个新的超级项目提交以记录新的子模块哈希ID,则需要某种方式来选择新的子模块提交哈希ID。 有多种方法可用,该名称是为其中的一种方法设计的。
假设子模块是一个公共仓库(可能在GitHub上),而你没有控制权,只是使用它。也许每年两次,或者每天50000次,有人更新了GitHub仓库。他们放到他们的主分支或开发分支上的新提交破坏了你使用的一些东西,但这不是问题,因为你的超级项目没有说“给我他们最新的主分支或开发分支提交”,你的超级项目说“给我提交a123456……”,而a123456……永远都是相同的提交,直到宇宙热死或我们停止使用Git,以先到者为准。但是,虽然他们破坏了你自己的软件,他们引入了一个你必须拥有的很酷的新功能。
此时,你想做的是让控制你的子模块的Git告诉你的子模块Git:“去获取他们的最新主分支或开发分支,或者无论我之前记录的名称是什么。”由于你确实记录了该名称,因此可以使用以下命令指示你的Git指示你的子模块执行该操作:
git submodule update --remote
你可以在其中添加一些额外的标志,例如--checkout、--rebase或--merge,但我不会涉及这些细节——我现在假设你直接使用它们的最新版本。你的Git运行git fetch并根据你的子模块副本中的分支名称指示更新你的子模块存储库到它们的最新提交。在所有这些过程中,至少涉及三个Git——你的超级项目、你的子模块和GitHub上的Git存储库,所以它有点复杂。他们,无论是谁,可能有一个或多个Git存储库用于控制GitHub上的存储库,但至少你不必处理这个问题。好吧,至少现在还没有。
现在你的子模块已经更新,你必须修复你自己的代码,既要使用新功能,也要处理他们对你已经使用的所有内容进行的所有破坏性更改。所以你完成了所有这些工作,构建和测试你的软件——所有这些都在你的本地机器上完成:这里没有涉及CI,至少现在没有——并让它们全部正常工作。现在你可以git add你的更改并git add子模块的名称。你的超级项目的索引和工作树现在全部匹配,你已准备好在超级项目中进行新提交。
请注意,
git add submodule-path 仅告诉你的Git在索引中记录当前子模块Git存储库中已检出的提交的哈希ID。再次强调,分支名称(如果有)是无关紧要的。您的子模块存储库是否在master或develop分支上,或者具有分离的HEAD都无关紧要;唯一重要的是原始提交哈希ID。
现在运行
git commit以进行新提交。控制哪个提交将被视为子模块的“正确”提交的索引中的哈希ID是您通过运行
git add submodule-path记录的提交哈希ID。在这种情况下,该提交ID因您之前运行
git submodule update --remote而被选中。但是,唯一重要的是索引中的哈希ID,它将进入新提交。
现在,您可以将此超级项目Git存储库中的提交推送到其他系统(例如CI系统)。它可以
git checkout此提交,并且此提交记录了正确的子模块哈希ID。
如何将其与CI系统结合使用,以便CI系统选择哈希ID?这可能更加困难,具体取决于您的CI系统是否提供此功能。
现在你已经知道了所有的构建方式,你需要的工具已经准备就绪。你必须让CI系统更新(或获取)超级项目的克隆版本。超级项目包含在其.gitmodules文件中,CI系统必须克隆任何子模块的URL和路径。它可能包含这些子模块的一些分支名称,也可能不包含。
现在,CI系统必须指示一些Git - 超级项目Git或子模块Git - 使子模块Git git checkout一些提交,而不是已记录为正确提交的提交,以便超级项目不再使用CI系统检出的提交。换句话说,你不再构建你提交给CI系统的内容。你正在让CI系统从不同的部分组成一个新的弗兰肯斯坦怪物:主体来自你的提交,但是某个部分来自其他提交,而你没有直接指定,而是允许其他人指定哪个提交放在那里。你给CI系统一个名称,并告诉它询问他们,无论他们是谁,都要确定该名称对应的哈希ID。
现在,你的CI系统可以尝试构建和使用这个弗兰肯斯坦怪物。如果一切顺利,你的CI系统将需要创建一个新的提交,该提交与你的提交非常相似,只是记录了子模块所得到的哈希ID,而这个ID来自于他们——无论他们是谁。此外,你的CI系统可能还需要获得推送此提交的权限,除非你的CI系统也是你的主要存储库源。