你可以避免在Fiddle中使用交叉表/多重左连接,而使用简单的条件聚合:
SELECT
end_user_id,
tms,
COALESCE(MAX(CASE WHEN type = 'IN_VEHICLE' THEN confidence END),0) AS IN_VEHICLE,
COALESCE(MAX(CASE WHEN type = 'ON_BICYCLE' THEN confidence END),0) AS ON_BICYCLE,
COALESCE(MAX(CASE WHEN type = 'ON_FOOT' THEN confidence END),0) AS ON_FOOT,
COALESCE(MAX(CASE WHEN type = 'RUNNING' THEN confidence END),0) AS RUNNING,
COALESCE(MAX(CASE WHEN type = 'STILL' THEN confidence END),0) AS STILL,
COALESCE(MAX(CASE WHEN type = 'TILTING' THEN confidence END),0) AS TILTING,
COALESCE(MAX(CASE WHEN type = 'UNKNOWN' THEN confidence END),0) AS UNKNOWN,
COALESCE(MAX(CASE WHEN type = 'WALKING' THEN confidence END),0) AS WALKING
FROM activities
GROUP BY end_user_id, tms
ORDER BY end_user_id, tms;
SqlFiddleDemo
输出:
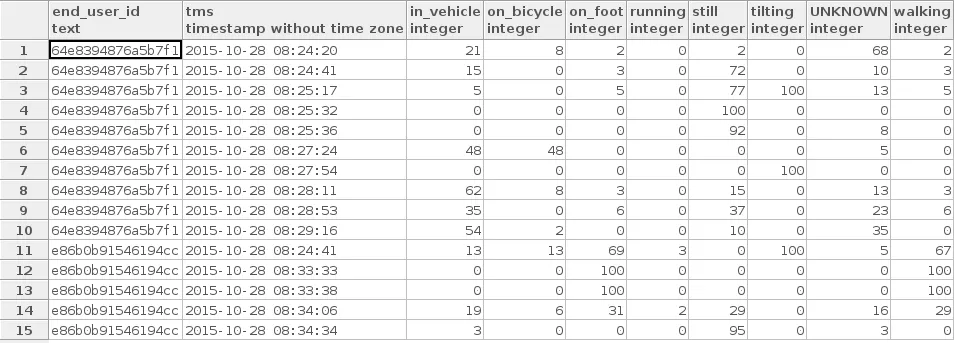
╔═══════════════════╦════════════════════════════╦═════════════╦═════════════╦══════════╦══════════╦════════╦══════════╦══════════╦═════════╗
║ end_user_id ║ tms ║ in_vehicle ║ on_bicycle ║ on_foot ║ running ║ still ║ tilting ║ unknown ║ walking ║
╠═══════════════════╬════════════════════════════╬═════════════╬═════════════╬══════════╬══════════╬════════╬══════════╬══════════╬═════════╣
║ 64e8394876a5b7f1 ║ October, 28 2015 08:24:20 ║ 21 ║ 8 ║ 2 ║ 0 ║ 2 ║ 0 ║ 68 ║ 2 ║
║ 64e8394876a5b7f1 ║ October, 28 2015 08:24:41 ║ 15 ║ 0 ║ 3 ║ 0 ║ 72 ║ 0 ║ 10 ║ 3 ║
║ 64e8394876a5b7f1 ║ October, 28 2015 08:25:17 ║ 5 ║ 0 ║ 5 ║ 0 ║ 77 ║ 100 ║ 13 ║ 5 ║
║ 64e8394876a5b7f1 ║ October, 28 2015 08:25:32 ║ 0 ║ 0 ║ 0 ║ 0 ║ 100 ║ 0 ║ 0 ║ 0 ║
║ 64e8394876a5b7f1 ║ October, 28 2015 08:25:36 ║ 0 ║ 0 ║ 0 ║ 0 ║ 92 ║ 0 ║ 8 ║ 0 ║
║ 64e8394876a5b7f1 ║ October, 28 2015 08:27:24 ║ 48 ║ 48 ║ 0 ║ 0 ║ 0 ║ 0 ║ 5 ║ 0 ║
║ 64e8394876a5b7f1 ║ October, 28 2015 08:27:54 ║ 0 ║ 0 ║ 0 ║ 0 ║ 0 ║ 100 ║ 0 ║ 0 ║
║ 64e8394876a5b7f1 ║ October, 28 2015 08:28:11 ║ 62 ║ 8 ║ 3 ║ 0 ║ 15 ║ 0 ║ 13 ║ 3 ║
║ 64e8394876a5b7f1 ║ October, 28 2015 08:28:53 ║ 35 ║ 0 ║ 6 ║ 0 ║ 37 ║ 0 ║ 23 ║ 6 ║
║ 64e8394876a5b7f1 ║ October, 28 2015 08:29:16 ║ 54 ║ 2 ║ 0 ║ 0 ║ 10 ║ 0 ║ 35 ║ 0 ║
║ e86b0b91546194cc ║ October, 28 2015 08:24:41 ║ 13 ║ 13 ║ 69 ║ 3 ║ 0 ║ 100 ║ 5 ║ 67 ║
║ e86b0b91546194cc ║ October, 28 2015 08:33:33 ║ 0 ║ 0 ║ 100 ║ 0 ║ 0 ║ 0 ║ 0 ║ 100 ║
║ e86b0b91546194cc ║ October, 28 2015 08:33:38 ║ 0 ║ 0 ║ 100 ║ 0 ║ 0 ║ 0 ║ 0 ║ 100 ║
║ e86b0b91546194cc ║ October, 28 2015 08:34:06 ║ 19 ║ 6 ║ 31 ║ 2 ║ 29 ║ 0 ║ 16 ║ 29 ║
║ e86b0b91546194cc ║ October, 28 2015 08:34:34 ║ 3 ║ 0 ║ 0 ║ 0 ║ 95 ║ 0 ║ 3 ║ 0 ║
╚═══════════════════╩════════════════════════════╩═════════════╩═════════════╩══════════╩══════════╩════════╩══════════╩══════════╩═════════╝
COALESCE也是冗余的(如果只允许正数/零值):
SELECT
end_user_id,
tms,
MAX(CASE WHEN type = 'IN_VEHICLE' THEN confidence ELSE 0 END) AS IN_VEHICLE,
MAX(CASE WHEN type = 'ON_BICYCLE' THEN confidence ELSE 0 END) AS ON_BICYCLE,
MAX(CASE WHEN type = 'ON_FOOT' THEN confidence ELSE 0 END) AS ON_FOOT,
MAX(CASE WHEN type = 'RUNNING' THEN confidence ELSE 0 END) AS RUNNING,
MAX(CASE WHEN type = 'STILL' THEN confidence ELSE 0 END) AS STILL,
MAX(CASE WHEN type = 'TILTING' THEN confidence ELSE 0 END) AS TILTING,
MAX(CASE WHEN type = 'UNKNOWN' THEN confidence ELSE 0 END) AS UNKNOWN,
MAX(CASE WHEN type = 'WALKING' THEN confidence ELSE 0 END) AS WALKING
FROM activities
GROUP BY end_user_id, tms
ORDER BY end_user_id, tms;
SqlFiddleDemo2
你也可以考虑为type列创建查找表,例如activities_type(type_id,type_name),而不是直接将字符串('IN_VEHICLE','ON_BICYCLE',...)存储在表中。
附录
我不是Postgresql专家,但经过一些尝试后:
SELECT
LEFT(end_user_id, strpos(end_user_id, '_')-1) AS end_user_id,
RIGHT(end_user_id, LENGTH(end_user_id) - strpos(end_user_id, '_'))::timestamp AS tms,
COALESCE(IN_VEHICLE,0) AS IN_VEHICLE,
COALESCE(ON_BICYCLE,0) AS ON_BICYCLE,
COALESCE(ON_FOOT,0) AS ON_FOOT,
COALESCE(RUNNING,0) AS RUNNING,
COALESCE(STILL,0) AS STILL,
COALESCE(TILTING,0) AS TILTING,
COALESCE("UNKNOWN",0) AS "UNKNOWN",
COALESCE(WALKING,0) AS WALKING
FROM crosstab(
'SELECT (end_user_id || ''_'' || tms) AS row_id, type, confidence
FROM activities
ORDER BY row_id, type, confidence',
'SELECT DISTINCT type FROM activities order by type'
) AS newtable (
end_user_id text,
IN_VEHICLE int,
ON_BICYCLE int,
ON_FOOT int,
RUNNING int,
STILL int,
TILTING int,
"UNKNOWN" int,
WALKING int)
ORDER BY end_user_id, tms;
为什么要连接和分割 end_user_id + tms?
因为crosstab(text,text)需要:
row_id <=> end_user_id + tms
category <=> type
value <=> confidence
请注意,此版本中没有
GROUP BY。
附录2 - 最终版本
基于 tablefunc模块文档 F.37.1.4. crosstab(text, text):
这样做更好,因为它可以处理row_id, extra_col1, extra_col2, category, value)。所以现在:
row_id <=> id
extra_col1 <=> end_user_id
extra_col2 <=> tms
...
最后一个查询:
SELECT
end_user_id,
tms,
coalesce(max(IN_VEHICLE), 0) as IN_VEHICLE,
coalesce(max(ON_BICYCLE), 0) as ON_BICYCLE,
coalesce(max(ON_FOOT), 0) as ON_FOOT,
coalesce(max(RUNNING), 0) as RUNNING,
coalesce(max(STILL), 0) as STILL,
coalesce(max(TILTING), 0) as TILTING,
coalesce(max("UNKNOWN"), 0) as "UNKNOWN",
coalesce(max(WALKING), 0) as WALKING
FROM crosstab(
'SELECT id,end_user_id , tms, type, confidence
FROM activities',
'SELECT DISTINCT type FROM activities order by type'
) AS newtable (
id INT,
end_user_id text,
tms timestamp,
IN_VEHICLE int,
ON_BICYCLE int,
ON_FOOT int,
RUNNING int,
STILL int,
TILTING int,
"UNKNOWN" int,
WALKING int
)
GROUP BY end_user_id, tms
ORDER BY end_user_id, tms;
活动类型表的意义是什么?
数据库规范化,您可以使用:
SELECT DISTINCT type FROM activities order by type
vs
SELECT type_name FROM activities_types ORDER BY type_name;
这个版本使用id作为row_id,因此仍然需要GROUP BY来压缩多行。
总之:条件聚合是最易读的解决方案。