2个回答
5
你在问题中提到了很多内容,所以我会尽力让它们更加清晰。以顺序执行的MIPS架构为例,它包含你提到的所有元素,除了可变长度指令。
许多MIPS CPU具有5级流水线,其中阶段为:
现在MUL和ADD都写入同一个寄存器。由于ADD比MUL早完成,它会完成WB并写入其结果。稍后,MUL也会这样做,R1将最终拥有错误(旧)的值。这就是需要流水线停顿的地方。解决这个问题的一种方法是防止ADD发出(从ID移动到EX阶段),直到MUL进入MEM阶段。这通过冻结或停滞管道来实现。引入浮点运算会导致类似的流水线问题。
我想补充一下关于定长与变长指令格式的话题(即使你没有明确要求)。MIPS(以及大多数RISC)CPU具有定长编码。这极大地简化了CPU流水线的实现,因为可以在单个周期内解码指令并读取输入寄存器(假设在给定的指令格式中寄存器位置是固定的,这对于MIPS是正确的)。此外,获取过程也变得简单,因为指令始终具有相同的长度,因此无需开始解码指令以查找其长度。
当然,这种方法也有缺点:生成紧凑的二进制代码的可能性降低了,这导致程序更大,从而导致缓存性能变差。此外,由于要从/向内存中读取/写入更多字节的数据,因此内存流量也增加了,这对于节能平台可能很重要。
这种优势导致一些RISC架构定义了16位指令长度模式(MIPS16或ARM Thumb),甚至是可变长度指令集(ARM Thumb2具有16位和32位指令)。与x86不同,Thumb2旨在使快速确定指令长度变得容易,因此CPU仍然容易解码。
这些压缩的ISA通常需要更多的指令来实现相同的程序,但如果代码获取是管道中指令吞吐量的瓶颈,则占用总空间更少且运行更快(小/不存在指令缓存以及从嵌入式CPU中的ROM中读取)。
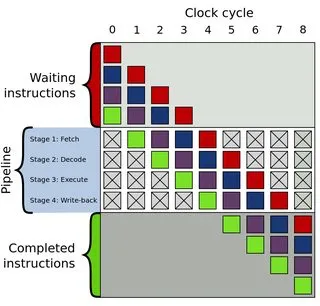
许多MIPS CPU具有5级流水线,其中阶段为:
IF -> ID -> EX -> MEM -> WB。(https://en.wikipedia.org/wiki/Classic_RISC_pipeline)。首先,让我们看一下那些每个阶段通常需要一个时钟周期的指令(例如SW(将字存储到内存)、BNEZ(非零分支)和ADD(将两个寄存器相加并存储到寄存器中))。并不是所有这些指令在所有流水线阶段都有有用的工作。例如,SW在WB阶段没有工作要做,BNEZ可以在ID阶段尽早完成(这是计算目标地址的最早时间),而ADD在MEM阶段没有工作要做。
无论如何,每个指令都会经过流水线的每个阶段,即使它们在某些阶段没有工作。指令将占用给定的阶段,但不会执行任何实际工作(例如,SW指令的WB阶段不会向寄存器写入结果)。换句话说,在这种情况下,不会出现停顿。
转向更复杂的指令,其EX阶段可能需要数十个周期,例如MUL或DIV。这里变得更加棘手。现在,即使按顺序获取指令(意味着WAW hazards现在是可能的),指令也可以以无序完成。请看以下示例:
MUL R1, R10, R11
ADD R2, R5, R6
MUL首先被获取并在ADD之前到达EX阶段,然而ADD将会在MUL的EX阶段运行超过10个时钟周期之前就完成。但是,在这个序列中不存在风险,因此管道不会在任何时候停顿-既不可能发生RAW风险也不可能发生WAW风险。再举一个例子:
MUL R1, R10, R11
ADD R1, R5, R6
现在MUL和ADD都写入同一个寄存器。由于ADD比MUL早完成,它会完成WB并写入其结果。稍后,MUL也会这样做,R1将最终拥有错误(旧)的值。这就是需要流水线停顿的地方。解决这个问题的一种方法是防止ADD发出(从ID移动到EX阶段),直到MUL进入MEM阶段。这通过冻结或停滞管道来实现。引入浮点运算会导致类似的流水线问题。
我想补充一下关于定长与变长指令格式的话题(即使你没有明确要求)。MIPS(以及大多数RISC)CPU具有定长编码。这极大地简化了CPU流水线的实现,因为可以在单个周期内解码指令并读取输入寄存器(假设在给定的指令格式中寄存器位置是固定的,这对于MIPS是正确的)。此外,获取过程也变得简单,因为指令始终具有相同的长度,因此无需开始解码指令以查找其长度。
当然,这种方法也有缺点:生成紧凑的二进制代码的可能性降低了,这导致程序更大,从而导致缓存性能变差。此外,由于要从/向内存中读取/写入更多字节的数据,因此内存流量也增加了,这对于节能平台可能很重要。
这种优势导致一些RISC架构定义了16位指令长度模式(MIPS16或ARM Thumb),甚至是可变长度指令集(ARM Thumb2具有16位和32位指令)。与x86不同,Thumb2旨在使快速确定指令长度变得容易,因此CPU仍然容易解码。
这些压缩的ISA通常需要更多的指令来实现相同的程序,但如果代码获取是管道中指令吞吐量的瓶颈,则占用总空间更少且运行更快(小/不存在指令缓存以及从嵌入式CPU中的ROM中读取)。
- dbajgoric
2
我认为“CPU必须找一些虚假的工作来做”是一种令人困惑的描述方式。一条指令可以只是坐在流水线阶段里不做任何工作,等待下一个时钟周期。除此之外,解释得很好。 - Peter Cordes
感谢Peter的输入,也感谢他扩展了我的回答。我实际上在最后一节中考虑提到ARM,但最终没有提及。我会编辑答案并替换掉令人困惑的“虚拟工作”部分。 - dbajgoric
3
实际上比你想象的更加复杂。
首先,CPU 不执行指令,而是执行 uops,其次,它可以乱序执行 uops。
uops
简单的指令转换为单个 uop,复杂的指令分成多个 uop。CPU 有一个 uop 缓存,保留最近的(例如1024)几个 uop。与完整指令相比,uop 更相似,因此在流水线中更容易匹配。
乱序执行
如果 CPU 需要等待计算结果,则查找不依赖于先前指令的 uops 并执行它们。
为了允许乱序执行,CPU 拥有一个寄存器文件,其中有比程序员可用的寄存器多得多的寄存器(例如256个通用寄存器)。它可以将其用作临时存储中间结果的工作区。
所有执行的指令都进入退役缓冲区,在原始顺序中输出结果。
缓冲区
除此之外,缓冲区解决了停顿问题。
指令被推测性地获取,并在缓冲区中等待解码。
X86/X64以其复杂的解码而闻名。AMD和英特尔通过投入大量硅来解决这个问题,使他们的CPU能够每个周期解码恒定数量的字节,与指令复杂度无关。指令的长度实际上并不重要,因为关键时间代码(紧密循环)是从uop-cache执行的,它不需要被解码。此外,解码通常被过度设计,以确保不成为瓶颈。 更多阶段
现代CPU有14个或更多阶段,而不是您设想的4个。 例如,可以查看AMD Zen架构的详细说明:https://www.extremetech.com/computing/234354-a-state-of-zen-amd-unveils-new-architectural-details-on-its-latest-cpu-core 因此,除了流水线之外,还有许多其他进程发生,所有这些进程都是为了防止停顿并填满气泡。
在实践中,现代处理器在将具有不同延迟的指令配对时并不会受到影响。使用低延迟uops已经在很大程度上消除了这个问题。 风险
您链接的维基百科文章已经很好地解释了它。现代CPU使用Tomasulo算法和寄存器重命名来防止气泡产生。
- Johan
1
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
nop,只有停顿。 - Ped7g