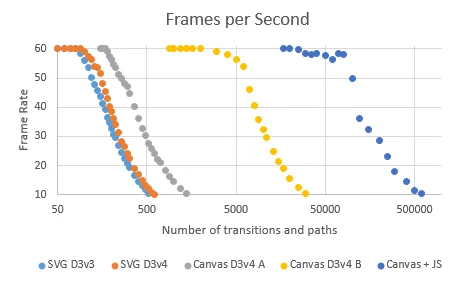
我已经通过以下代码了解了“点沿路径”d3可视化:https://bl.ocks.org/mbostock/1705868。我注意到,在点沿路径移动时,它会占用7到11%的CPU使用率。
当前情况是,我有大约100个路径,在每条路径上,我都需要将点(圆圈)从源移动到目标。因此,由于更多数量的点同时移动,它消耗了超过90%的CPU内存。
我尝试了以下方法:
当前情况是,我有大约100个路径,在每条路径上,我都需要将点(圆圈)从源移动到目标。因此,由于更多数量的点同时移动,它消耗了超过90%的CPU内存。
我尝试了以下方法:
function translateAlong(path) {
var l = path.getTotalLength();
return function(d, i, a) {
return function(t) {
var p = path.getPointAtLength(t * l);
return "translate(" + p.x + "," + p.y + ")";
};
};
}
// On each path(100 paths), we are moving circles from source to destination.
var movingCircle = mapNode.append('circle')
.attr('r', 2)
.attr('fill', 'white')
movingCircle.transition()
.duration(10000)
.ease("linear")
.attrTween("transform", translateAlong(path.node()))
.each("end", function() {
this.remove();
});
那么降低CPU使用率的更好方法是什么呢? 谢谢。