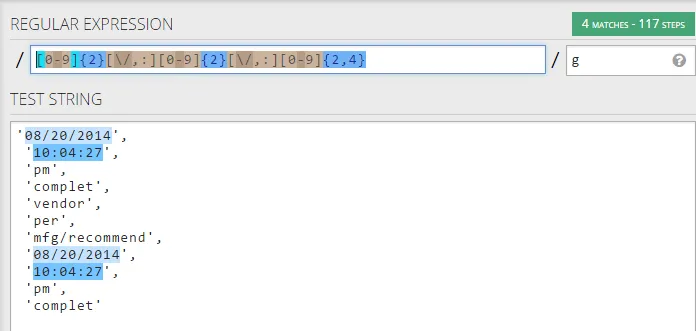
描述
^(?:(?:[0-9]{2}[:\/,]){2}[0-9]{2,4}|am|pm)$
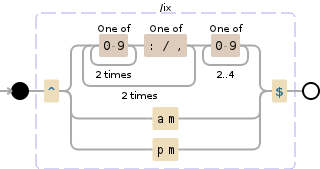
这个正则表达式会执行以下操作:
- 查找看起来像日期
12/23/2016 和时间 12:34:56 的字符串
- 查找还包括也是
am 或 pm,它们可能是源列表中前一个时间的一部分
示例
演示实例
示例列表
08/20/2014
10:04:27
pm
complete
vendor
per
mfg/recommend
08/20/2014
10:04:27
pm
complete
处理后的列表
complete
vendor
per
mfg/recommend
complete
示例Python脚本
import re
SourceList = ['08/20/2014',
'10:04:27',
'pm',
'complete',
'vendor',
'per',
'mfg/recommend',
'08/20/2014',
'10:04:27',
'pm',
'complete']
OutputList = filter(
lambda ThisWord: not re.match('^(?:(?:[0-9]{2}[:\/,]){2}[0-9]{2,4}|am|pm)$', ThisWord),
SourceList)
for ThisValue in OutputList:
print ThisValue
解释
NODE EXPLANATION
^ the beginning of the string
(?: group, but do not capture:
(?: group, but do not capture (2 times):
[0-9]{2} any character of: '0' to '9' (2 times)
[:\/,] any character of: ':', '\/', ','
){2} end of grouping
[0-9]{2,4} any character of: '0' to '9' (between 2
and 4 times (matching the most amount
possible))
| OR
am 'am'
| OR
pm 'pm'
) end of grouping
$ before an optional \n, and the end of the
string