我会假设您不想使用gensim,并希望坚持使用tensorflow。在这种情况下,我将提供两个选项:
选项1-Tensorboard:
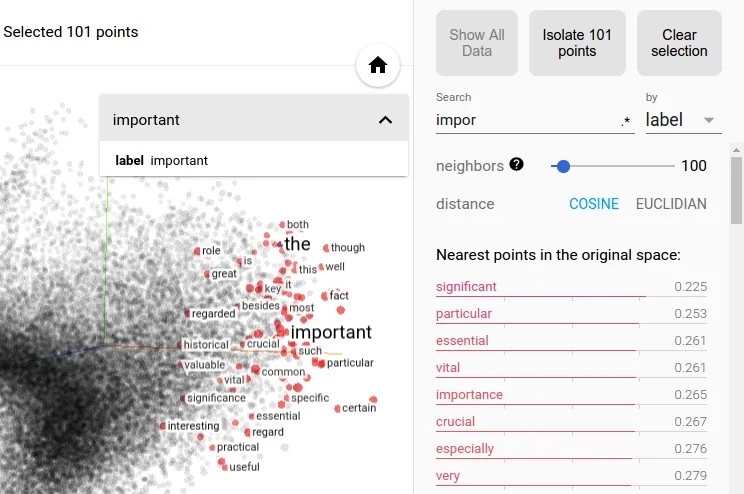
如果您只是从探索的角度尝试此操作,则建议使用Tensorboard的嵌入可视化器来搜索最接近的嵌入。它提供了一个很酷的界面,您可以使用余弦和欧几里得距离以及一组邻居。
Tensorflow文档链接
选项2-直接计算
在word2vec_basic.py文件中,有一个他们正在计算最接近单词的例子,如果稍微修改该函数,则可以使用该函数。以下内容在图形本身中找到:
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(
normalized_embeddings, valid_dataset)
similarity = tf.matmul(
valid_embeddings, normalized_embeddings, transpose_b=True)
接着,在训练过程中(每10000步),他们会运行以下代码(在会话处于活动状态时)。当他们调用similarity.eval()时,它会获取图中相似度张量的字面numpy数组评估。
if step % 10000 == 0:
sim = similarity.eval()
for i in xrange(valid_size):
valid_word = reverse_dictionary[valid_examples[i]]
top_k = 8
nearest = (-sim[i, :]).argsort()[1:top_k+1]
log_str = "Nearest to %s:" % valid_word
for k in xrange(top_k):
close_word = reverse_dictionary[nearest[k]]
log_str = "%s %s," % (log_str, close_word)
print(log_str)
如果您想为自己进行适应,您需要对更改reverse_dictionary[valid_examples[i]]进行一些微调,使其成为您要获取k个最接近单词的单词索引。