从数据结构的角度来看,Lucene(Solr/ElasticSearch)是如何快速进行过滤术语计数的?例如,给定包含单词“bacon”的所有文档,查找这些文档中所有单词的计数。
首先,为了背景,我了解到Lucene依赖于类似于CONCISE的压缩位数组数据结构。在概念上,这个位数组对于每个不匹配术语的文档都保持0,对于每个匹配术语的文档都保持1。但酷/令人惊叹的部分是,这个数组可以高度压缩,并且在布尔运算方面非常快。例如,如果您想知道哪些文档包含术语“red”和“blue”,则获取与“red”对应的位数组和与“blue”对应的位数组,并将它们AND在一起,以获取与匹配文档相对应的位数组。
但是,Lucene如何快速确定与“bacon”匹配的所有文档中单词的计数?在我天真的理解中,Lucene必须将与bacon相关联的位数组与每个其他单词的位数组进行AND运算。我错过了什么吗?我不明白这怎么可能是有效的。此外,这些位数组是否必须从磁盘上取出?那听起来更糟糕!魔法是如何运作的?
首先,为了背景,我了解到Lucene依赖于类似于CONCISE的压缩位数组数据结构。在概念上,这个位数组对于每个不匹配术语的文档都保持0,对于每个匹配术语的文档都保持1。但酷/令人惊叹的部分是,这个数组可以高度压缩,并且在布尔运算方面非常快。例如,如果您想知道哪些文档包含术语“red”和“blue”,则获取与“red”对应的位数组和与“blue”对应的位数组,并将它们AND在一起,以获取与匹配文档相对应的位数组。
但是,Lucene如何快速确定与“bacon”匹配的所有文档中单词的计数?在我天真的理解中,Lucene必须将与bacon相关联的位数组与每个其他单词的位数组进行AND运算。我错过了什么吗?我不明白这怎么可能是有效的。此外,这些位数组是否必须从磁盘上取出?那听起来更糟糕!魔法是如何运作的?
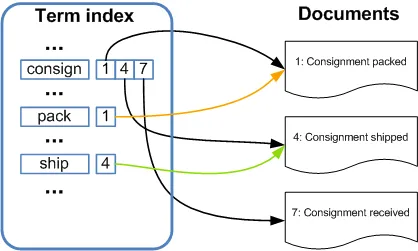 为了实现这一点,Lucene将文档、索引及其元数据存储在不同的文件格式中。有关文件详细信息,请参阅此链接:
为了实现这一点,Lucene将文档、索引及其元数据存储在不同的文件格式中。有关文件详细信息,请参阅此链接: