我正在尝试理解正则表达式,在处理长度为10的数字时,我只需要进行如下操作:
/^[0-9]{10}$/
仅针对连字符,我可以做到
/^[-]$/
使用组合表达式将两者结合在一起将导致
/^([0-9]{10})|([-])$/
这个表达式并没有按照预期工作,如果字符串无效,它会匹配部分字符串而不是完全不匹配。

如何创建只接受"-"或10位数字的正则表达式?
我正在尝试理解正则表达式,在处理长度为10的数字时,我只需要进行如下操作:
/^[0-9]{10}$/
仅针对连字符,我可以做到
/^[-]$/
/^([0-9]{10})|([-])$/
这个表达式并没有按照预期工作,如果字符串无效,它会匹配部分字符串而不是完全不匹配。
如何创建只接受"-"或10位数字的正则表达式?
你可以将你的两个正则表达式精确地组合起来,这样就可以正常工作。换句话说,只需使用交替/管道操作符进行组合即可。
/^[0-9]{10}$/
and
/^[-]$/
/^[0-9]{10}$|^[-]$/
↑↑↑↑↑↑↑↑↑↑↑ ↑↑↑↑↑ YOUR ORIGINAL REGEXPS, COMBINED AS IS WITH |
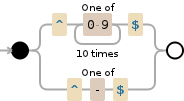
/^[0-9]{10}$|^-$/
↑ SIMPLIFY [-] TO JUST -
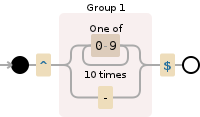
^开头和$结尾。这有点重复,也使得很难立即看出正则表达式总是从开头匹配到结尾。因此,我们可以按照其他答案中所解释的方法,将^和$从两个子正则表达式中取出,并使用分组运算符()组合它们的内容:/^([0-9]{10}|-)$/
↑↑↑↑↑↑↑↑↑↑↑↑↑ GROUP REGEXP CONTENTS WITH PARENS, WITH ANCHORS OUTSIDE
相应的可视化结果如下所示:
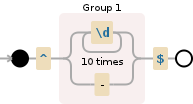
虽然以上也可以正常工作,但你也可以使用 \d 替代 [0-9],这样最终的、最简单的版本就是:
/^(\d{10}|-)$/
↑↑ USE \d FOR DIGITS
这个可以用可视化来表示:
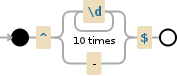
如果由于某些原因您不想“捕获”该组,请使用(?:,例如
/^(?:\d{10}|-)$/
↑↑ DON'T CAPTURE THE GROUP
现在的可视化展示了该组未被捕获:
顺便提一下,在您原始尝试将两个正则表达式组合时,我注意到您将它们加以括号表示,如下:
/^([0-9]{10})|([-])$/
↑↑↑↑↑↑↑↑↑↑↑ ↑↑↑↑↑ YOU PARENTHESIZED THE SUB-REGEXPS
实际上这并不是必要的,因为管道(或选择)操作符已经具有很低的优先级(实际上它是任何正则表达式操作符中优先级最低的);"低优先级"意味着它只会在两侧的内容已经处理完后才会应用,所以你在这里写的与下面的相同:
/^[0-9]{10}|[-]$/
然而,从其可视化效果可以看出,对于其他回答中提到的原因,它仍然无法正常工作:
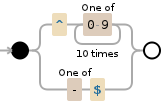
/^([0-9]{10}|-)$/
你的正则表达式中的括号放错位置了,只是断言最后有连字符存在。
以下是 OP 正则表达式的有效分解:
^([0-9]{10}) # matches 10 digits at start
| # OR
([-])$ # matches hyphen at end
1234567890111
1234----
------------------
1234567890--------
/^[-]$/,我相信这是他想要的。 - pah^([0-9]{10}),要么以“-”结尾,即([-])$。您需要添加额外的包装^( .. )$才能使其起作用。例如:/^(([0-9]{10})|([-]))$/
/^([0-9]{10}|-)$/,因为[-]和-是相同的。
a|b是一个替代项:匹配a或b。 在这里,你的a模式是^([0-9]{10}),而你的b模式是([-])$。 添加括号将选项限制为不包括^和$。 - Ry-