我正在学习编程语言,对于“何时是一个函数另一个函数的子类型”这个问题的答案让我感到非常反直觉。
为了澄清:假设我们有以下类型关系:
bool<int<real
(real->bool) 是 (int->bool) 的子类型?不应该是反过来吗?我期望函数的子类型规则是:如果f2可以接受f1所能接受的任何参数,并且f1只返回f2也会返回的值,则f1是f2的子类型。显然,f1可以接受f2不能接受的值。
我正在学习编程语言,对于“何时是一个函数另一个函数的子类型”这个问题的答案让我感到非常反直觉。
为了澄清:假设我们有以下类型关系:
bool<int<real
(real->bool) 是 (int->bool) 的子类型?不应该是反过来吗?以下是函数子类型的规则:
参数类型必须是反变型,返回类型必须是协变型。
协变型 == 保持对结果参数类型的"A是B的子类型"层次结构。
反变型 == 颠倒("违背")参数类型的层次结构。
因此,在您的示例中:
f1: int -> bool
f2: real -> bool
f1: {x,y,z} -> {x,y}
f2: {x,y} -> {x,y,z}
F1 = f1;
F2 = f2;
{a,b} = F1({1,2,3}); // call F1 with a {x,y,z} struct of {1,2,3}; This works.
{a,b,c} = F2({1,2}); // call F2 with a {x,y} struct of {1,2}. This also works.
// Now take F2, but treat it like an F1. (Which we should be able to do,
// right? Because F2 is a subtype of F1). Now pass it in the argument type
// F1 expects. Does our assignment still work? It does.
{a,b} = ((F1) F2)({1,2,3});
这里有另一个答案,因为虽然我理解函数子类型规则是有道理的,但我想深入探讨为什么其他任何参数/结果子类型组合都不行。

T1 <:S1),并且它返回的结果不会使上下文感到惊讶(S2 <:T2),就可以安全地允许使用类型为S1 → S2的函数在期望另一种类型T1 → T2的上下文中使用。"
再次说明,这对我来说是有意义的,但我想看看为什么没有其他组合的打字规则是有意义的。为此,我查看了一个简单的高阶函数和一些示例记录类型。
对于以下所有示例,请让:
S1 := {x,y}T1 := {x,y,z}T2 := {a}S2 := {a,b}让:
f1 具有类型 S1 → S2 ⟹ {x, y} → {a, b}f2 具有类型 T1 → T2 ⟹ {x, y, z} → {a}现在假设 type(f1) <: type(f2)。我们从上面的规则中知道了这一点,但是让我们假装不知道并看看为什么这是有意义的。
map( f2 : {x, y, z} → {a}, L : [ {x, y, z} ] ) : [ {a} ]
如果我们用 f1 替换 f2,我们得到:map( f1 : {x, y} → {a, b}, L : [ {x, y, z} ] ) : [ {a, b} ]
这样做是可行的,因为:
f1 如何处理其参数,它都可以忽略额外的 z 记录字段而不会出现问题。map 的上下文如何处理结果,它都可以忽略额外的 b 记录字段而不会出现问题。总结:
{x, y} → {a, b} ⟹ {x, y, z} → {a} ✔
设:
f1 其类型为 T1 → S2 ⟹ {x, y, z} → {a, b}f2 其类型为 S1 → T2 ⟹ {x, y} → {a}假设 type(f1) <: type(f2)
我们运行 map( f2 : {x, y} → {a}, L : [ {x, y} ] ) : [ {a} ]
如果我们用 f1 来替换 f2,我们会得到:
map( f1 : {x, y, z} → {a, b}, L : [ {x, y} ] ) : [ {a, b} ]
f1期望并可能在L列表中的任何记录中操作z记录字段,而这样的字段不存在。⚡f1的类型为S1 → T2 ⟹ {x,y} → {a}
2. f2的类型为T1 → S2 ⟹ {x,y,z} → {a,b}
假设type(f1) <: type(f2)
我们运行map( f2 : {x, y, z} → {a, b}, L : [ {x, y, z} ] ) : [ {a, b} ]
如果我们用f1替换f2,我们得到:map( f1 : {x, y} → {a}, L : [ {x, y, z} ] ) : [ {a} ]
f1 的 z 记录字段,但如果调用 map 的上下文期望一个带有 b 字段的记录列表,我们将会遇到错误。⚡
查看上面的两个示例,可以看出这两个地方可能出错。
这是一个非常冗长而详细的答案,但我必须记录下这些东西,以便弄清楚其他参数和返回值子类型化为什么无效。既然我已经写了一些东西,那么为什么不在这里发布呢。
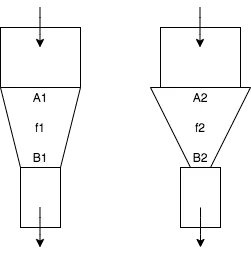
f2 替换漏斗 f1,那么:
A2 必须不小于 A1。B2 需要不大于 B1。f2 能够替换 f1,则:
f2 的输入集 A2 需要涵盖所有可能的 f1 输入,即 A1 <: A2,并且f2 的输出集 B2 需要符合 f1 所需的,即 B2 <: B1A1 <: A2 并且 B1 >: B2,那么 f1: A1 => B1 >: f2: A2 => B2。借鉴自TAPL:
S是T的子类型,即如果S类型的任何项可以在期望T类型的上下文中使用,则S <: T。将此应用于函数子类型化F <: G意味着F类型的任何函数都可以在期望G类型的上下文中使用。
子类型的其他直觉包括:
- S描述的每个值也由T描述
- S的元素是T元素的子集
让我们使用直觉2.来检查以下函数子类型化,以确定在期望T1 → T2的上下文中使用$ S_1 \to S_2 $是否安全。
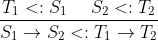
超集,即所有必需的参数都应该存在,额外的参数可以存在,我们可以简单地不处理额外的参数;而返回值 $ S_2 $ 应该是 $ T_2 $ 的 子集,以避免在通常调用/应用 $ T_1 \to T_2$ 的上下文中产生意外。myFuncB传递字符串,
而我们却传递了数字和布尔值。typedef FuncTypeA = Object Function(Object obj); // (Object) => Object
typedef FuncTypeB = String Function(String name); // (String) => String
void process(FuncTypeA myFunc) {
myFunc("Bob").toString(); // Ok.
myFunc(123).toString(); // Fail.
myFunc(true).toString(); // Fail.
}
FuncTypeB myFuncB = (String name) => name.toUpperCase();
process(myFuncB);
然而,下面的代码将会工作,因为现在你可以传递任何类型的对象到myFuncB中,
而我们只传递字符串。
typedef FuncTypeA = Object Function(String name); // (String) => Object
typedef FuncTypeB = String Function(Object obj); // (Object) => String
void process(FuncTypeA myFuncA) {
myFunc("Bob").toString(); // Ok.
myFunc("Alice").toString(); // Ok.
}
FuncTypeB myFuncB = (Object obj) => obj.toString();
process(myFuncB);