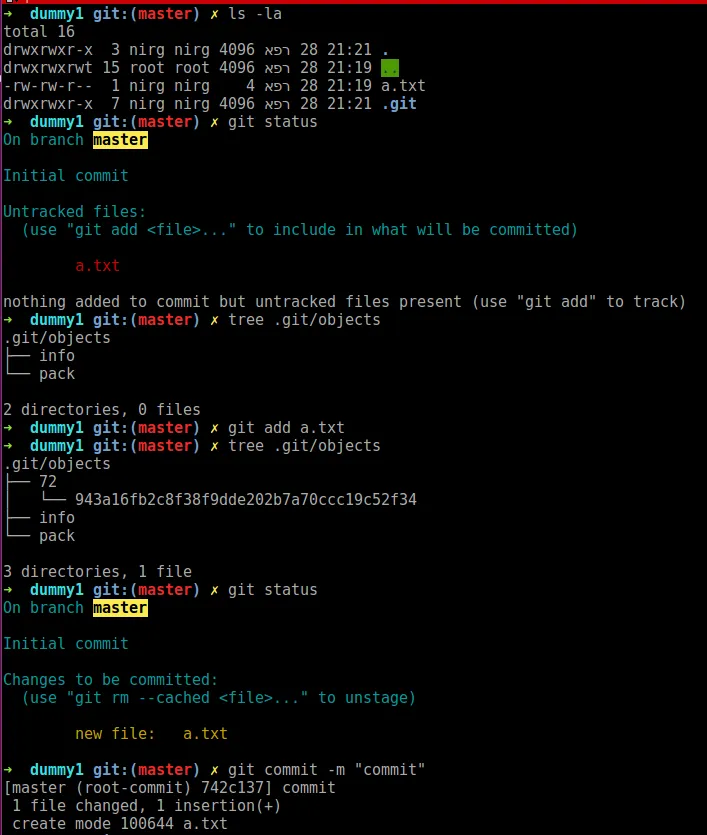
根据Git对象模型,文件和文件夹通过它们的sha1哈希值保存到.git文件夹中的特定位置。
Git如何内部知道文件是否已删除、添加或编辑(具体而言,当您键入
Git如何内部知道文件是否已删除、添加或编辑(具体而言,当您键入
git status时如何计算所见到的更改)?系统是否仅通过sha1来确定此信息?git status时如何计算所见到的更改)?系统是否仅通过sha1来确定此信息?pack(*1- 见下文)中,而名称则存储在idx中。git status时,Git会检查是否已经在idx文件(元数据)中存在此路径,并根据结果决定它是否为新文件。当您执行git status时,git会搜索您的工作目录,寻找idx文件中“注册”的路径与您的工作目录之间的匹配。
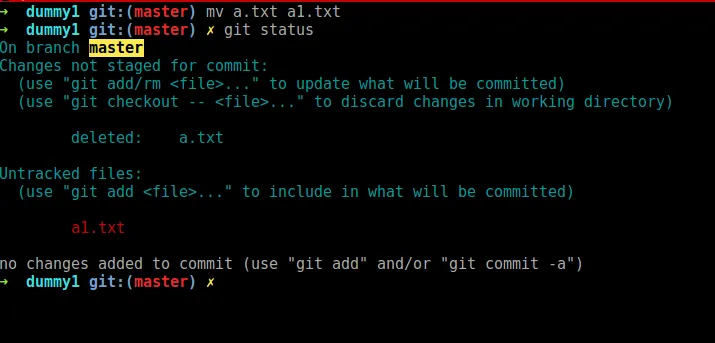
当您使用mv移动文件时,您的工作目录没有存储由git存储的“原始”路径,因此由于git无法再找到“注册”的路径,该文件被标记为已删除。
但是同时,git看到了一个新文件,即您刚刚移动文件到的新路径,因此新文件将被标记为新文件。
另一方面,当使用git mv时,git会更新元数据以指向新名称,并将内容标记为重命名。在这种情况下,git会更新idx文件中文件的注册路径。
如果同时移动和更新,则也将标记为重命名+修改。
使用 git ls-tree 内部命令来查找您的文件的SHA-1值。

注意
当您将内容添加到暂存区时,Git开始跟踪它。
一旦文件被添加,Git会在文件中存储以下信息。
[blob][1 white space][content length][null][content]
If you have a file with the string `hello` it will look like this:
blob 5\0Hello
sha1sumn计算此文件的SHA-1值,将其与z-lib压缩,并使用此SHA-1作为名称保存文件在`.git/objects'下。
为了展示git实际上使用了上述描述的内容,这里是与git在幕后执行以计算SHA-1的相同命令。

(http://shafiulazam.com/gitbook/1_the_git_object_model.html)
CodeWizard's answer 在一些重要细节上是错误的,正如Edward Thomson在评论中所指出的那样。
超短版本是 git status 运行了 git diff。
事实上,它运行了两次,或者更准确地说,它运行了两个不同的内部变体 git diff:一个用于比较HEAD和索引/暂存区,另一个用于比较暂存区和工作目录。它使用请求搜索重命名的方式运行每个diff,即设置了 -M 标志(见下文)。最后,它以您请求的任何格式向您呈现这些diff的结果。但是,在任何情况下,它都不会显示文件之间的实际更改(因此实际上它使用了 --name-status 运行这些 diffs)。
你可以手动运行这两个内部差异: 一个前端命令拼写为git diff-index --cached, 另一个前端命令拼写为git diff-files。这个前端选择被捕获在略微奇怪的原始输出格式部分中(我已经稍微修改了一下以在StackOverflow上更好地显示):
(您也可以使用常规的
git-diff-index、git-diff-tree、git-diff-files和git diff --raw的原始输出格式非常相似。这些命令都比较两组东西;比较的内容不同:
git-diff-index tree-ish
比较tree-ish和文件系统上的文件。
git-diff-index --cached tree-ish
比较tree-ish和索引。
git-diff-tree [-r] tree-ish-1 tree-ish-2 [pattern ...]
比较由两个参数指定的树。
git-diff-files [pattern ...]
比较索引和文件系统上的文件。
git diff调用它们: git diff --cached将当前(HEAD)提交与暂存区进行比较,而没有其他参数的git diff将暂存区与工作树进行比较。)
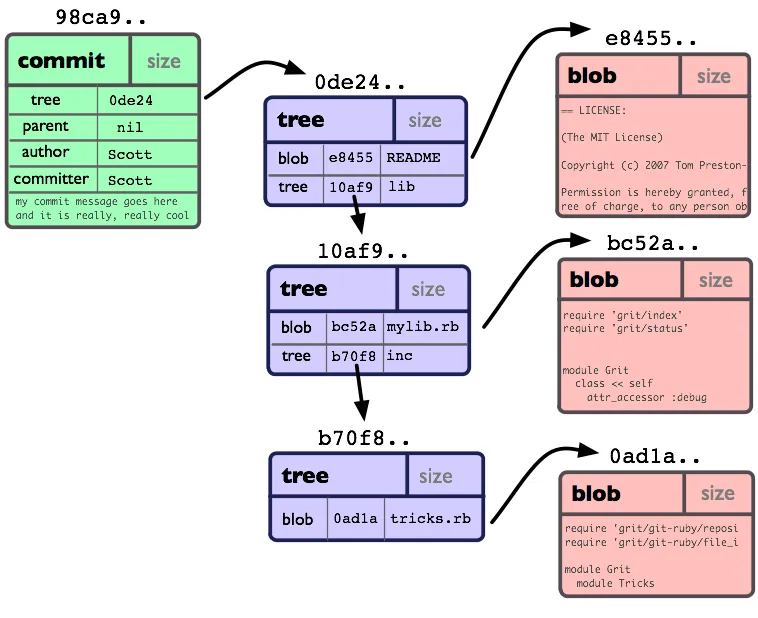
CodeWizard的答案包含了此过程的关键。基本上,一个tree对象包含路径名组件(例如foo/bar中的foo或bar)和另一个对象ID。如果该组件代表目录,则对象ID定位到另一个树对象;如果它代表文件,则对象ID定位到一个blob对象。在任何情况下,ID都是Git的内部名称,这使Git可以在存储库中找到它。
VeryLongDirectory/AnotherLongDirectory/bar followed by VeryLongDirectory/AnotherLongDirectory/baz does not have to spell out VeryLongDirectory/AnotherLongDirectory each time.)100644 or 100755; the final rwx bits are set based on your umask, assuming a Unix-like host, with x being always-clear if the stored mode is 100644, otherwise set-except-as-cleared-by-umask.)
一个文件如果在工作树中,但既不在Git是如何内部判断文件是否被删除、添加或编辑的(具体来说,当你输入git status时它是如何计算变更的)?
HEAD提交中也不在索引/暂存区中,则是未暂存的(这实际上就是“未暂存”的定义)。Git通过查看所有三个位置(并使用索引/暂存区作为缓存信息以加速进程)来查找这些文件。所有未暂存的文件路径通常会被传递给“忽略”代码,如果它们在.gitignore或任何其他忽略某些路径的文件中列出,则会使git保持安静。
处理完未暂存的路径后,让我们考虑剩余的路径,这些路径(根据定义)至少出现在HEAD或索引/暂存区中的一个中。
git status没有设置任何细节控制标志,但Git首先将“A”侧(a/foo/bar)中可用的路径名与“B”侧(b/foo/bar)中可用的路径名进行比较。如果相同的路径出现在两个侧面,那么文件很可能只是在原地修改,Git就会从这个假设开始。如果一个路径出现在A侧但不在B侧,而另一个路径出现在B侧但不在A侧,则这两个路径会被配对并交给重命名检测器(如果启用了)。-M或--find-renames。
-M[n] --find-renames[=n]检测重命名。如果指定了n,则它是相似性指数(即添加/删除与文件大小相比的数量)的阈值。例如,
-M90%表示Git应该将删除/添加对视为重命名,如果文件中有超过90%的内容没有更改。没有%符号,则该数字应被视为分数,小数点前面有一个点。即,-M5变成0.5,因此与-M50%相同。类似地,-M05等同于-M5%。要将检测限制为精确重命名,请使用-M100%。默认相似性指数为50%。
将diff.renameLimit设置为0,可以在配置中默认启用重命名检测。否则,默认情况下当前已禁用此功能,但在即将发布的Git版本中将默认启用(我不确定是哪个版本)。
如需了解相似匹配的详细信息,请参见 Edward Thomson 的此答案。
一旦重命名检测器确定某个A到B的更改是一个重命名,它就会将两个名称从“仅在A中”的列表和“仅在B中”的列表中提取出来。
运行重命名检测器(如果启用),任何仅在A侧找到的文件都被视为“已删除”,任何仅在B侧找到的文件都被视为“已添加”。对于git status,这结束了整个过程(除了显示结果)。对于常规的git diff,当某个文件被修改或重命名并修改时,我们通常会继续生成实际的差异输出。
(请注意,Git的所有差异都共享这些机制,因此只要打开重命名检测并设置相同的阈值,它们都将找到相同的重命名。这些也在git merge期间使用。)
hg mv等。这是因为它们会在每次提交时记录重命名。这种系统必须为每个文件分配某种标识符(这可以是ClearCase中的真实对象ID,也可以只是“当前提交中的名称”,然后根据需要进行修改,随着我们从提交到提交移动)。这种系统的优点是VCS可以跟踪文件,无论其变化如何。缺点是您必须记录更改,而意外删除然后恢复的文件可能会获得新ID(请参见ClearCase的“evil twins”)。git mv:你可以git rm --cached旧路径并git add新路径,以达到同样的效果。(当然,你也可以在方便的时候使用git mv,而大多数情况下这是更方便的。但这与记录每个检入或提交时目录修改的版本控制系统有着显著的不同:对于这些系统,你必须调用特定于VCS的mv命令,如hg mv或cleartool mv,来通知VCS文件已移动,而不是让VCS稍后弄清楚。)你不必使用 git mv。如果你重命名一个文件(mv)而没有使用 git mv,git 会将其视为新文件进行跟踪。(参考这个例子 - http://i.stack.imgur.com/yCUeT.png)所以根据你的说法,git 应该将其视为重命名,但实际上并没有。我在这里错过了什么? - CodeWizardmv foo bar),Git将不知道要执行 git add bar 和 git rm --cached foo 直到您告诉它为止。一旦您告诉了Git,Git就会再次跟上进度。使用 git mv foo bar 将同时重命名文件并告诉Git删除旧的索引条目并添加新的索引条目,所有这些都可以通过一个方便的步骤完成,因此这是最好的方法 - 它只是从技术上讲不是必需的,因为Git会在稍后处理其余部分时自动解决。 (在Mercurial中,hg mv 是必需的,但如果您已经在 hg 外部进行了 mv,则可以拼写为 hg mv --after。[续]) - torek