我正在尝试对我的应用程序进行剖析,以监视函数的效果,在重构之前和之后都要这样做。我已经对我的应用程序进行了分析,并查看了汇总信息。我注意到 热点路径 列表中没有提到我使用的任何函数,它只提到了 Application.Run() 函数。
我对剖析不太熟悉,想知道如何获取有关热点路径的更多信息,就像 MSDN 文档 所演示的那样; MSDN 示例: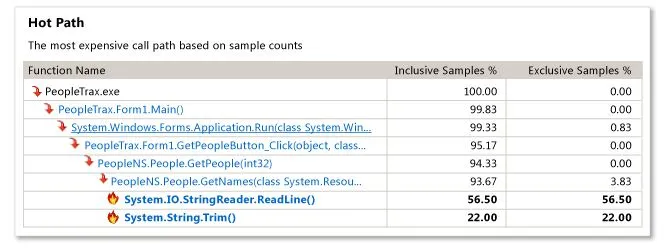 我的结果:
我的结果:
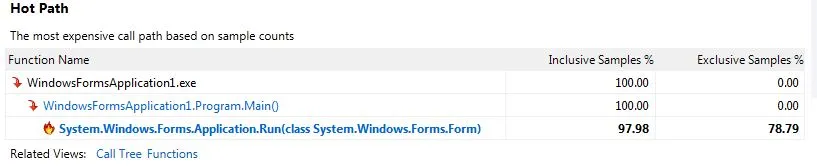 我在输出窗口中注意到有许多与加载符号失败相关的消息,其中一些如下:
我在输出窗口中注意到有许多与加载符号失败相关的消息,其中一些如下:
感谢任何指导。
我对剖析不太熟悉,想知道如何获取有关热点路径的更多信息,就像 MSDN 文档 所演示的那样; MSDN 示例:
我的结果:
我在输出窗口中注意到有许多与加载符号失败相关的消息,其中一些如下:Failed to load symbols for C:\Windows\system32\USP10.dll.
Failed to load symbols for C:\Windows\system32\CRYPTSP.dll.
Failed to load symbols for (Omitted)\WindowsFormsApplication1\bin\Debug\System.Data.SQLite.dll.
Failed to load symbols for C:\Windows\system32\GDI32.dll.
Failed to load symbols for C:\Windows\WinSxS\x86_microsoft.windows.common-controls_6595b64144ccf1df_6.0.7601.17514_none_41e6975e2bd6f2b2\comctl32.dll.
Failed to load symbols for C:\Windows\system32\msvcrt.dll.
Failed to load symbols for C:\Windows\Microsoft.NET\Framework\v4.0.30319\nlssorting.dll.
Failed to load symbols for C:\Windows\Microsoft.Net\assembly\GAC_32\System.Data\v4.0_4.0.0.0__b77a5c561934e089\System.Data.dll. Failed to load symbols for
C:\Windows\Microsoft.Net\assembly\GAC_32\System.Transactions\v4.0_4.0.0.0__b77a5c561934e089\System.Transactions.dll.
Unable to open file to serialize symbols: Error VSP1737: File could not be opened due to sharing violation: - D:\(Omitted)\WindowsFormsApplication1110402.vsp
感谢任何指导。