我有一份宠物列表:

我需要从主人表中找到每只宠物的正确主人
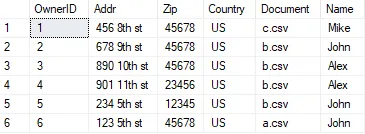
为了正确地将每只宠物与其主人匹配,我需要使用一个特殊的匹配表,它看起来像这样:
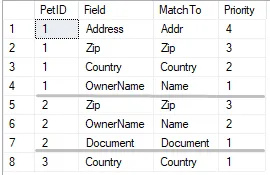
因此,对于PetID = 2的宠物,我需要找到一个符合三个字段的匹配的主人:
Pet.Zip = Owner.Zip
and Pet.OwnerName = Owner.Name
and Pet.Document = Owner.Document
select top 1 OwnerID from owners
where Zip = 23456
and Name = 'Alex'
and Document = 'a.csv'
在我们的例子中:
select top 1 OwnerID from owners where
Name = 'Alex'
and Document = 'a.csv'
由于找不到记录,我们需要在较少的字段上进行匹配。以我们的示例为例:
select top 1 OwnerID from owners where Document = 'a.csv'
现在,我们找到了OwnerID = 6的所有者。
现在,我们需要更新OwnerID = 6的宠物,然后才能处理下一个宠物。
目前,我能想到的唯一方法涉及到使用循环或游标+动态SQL。
是否有可能在不使用循环+动态SQL的情况下实现这一点?也许可以用STUFF + Pivot来解决?
sql fiddle: http://sqlfiddle.com/#!18/10982/1/0
样例数据:
create table temp_builder
(
PetID int not null,
Field varchar(30) not null,
MatchTo varchar(30) not null,
Priority int not null
)
insert into temp_builder values
(1,'Address', 'Addr',4),
(1,'Zip', 'Zip', 3),
(1,'Country', 'Country', 2),
(1,'OwnerName', 'Name',1),
(2,'Zip', 'Zip',3),
(2,'OwnerName','Name', 2),
(2,'Document', 'Document', 1),
(3,'Country', 'Country', 1)
create table temp_pets
(
PetID int null,
Address varchar(100) null,
Zip int null,
Country varchar(100) null,
Document varchar(100) null,
OwnerName varchar(100) null,
OwnerID int null,
Field1 bit null,
Field2 bit null
)
insert into temp_pets values
(1, '123 5th st', 12345, 'US', 'test.csv', 'John', NULL, NULL, NULL),
(2, '234 6th st', 23456, 'US', 'a.csv', 'Alex', NULL, NULL, NULL),
(3, '345 7th st', 34567, 'US', 'b.csv', 'Mike', NULL, NULL, NULL)
create table temp_owners
(
OwnerID int null,
Addr varchar(100) null,
Zip int null,
Country varchar(100) null,
Document varchar(100) null,
Name varchar(100) null,
OtherField bit null,
OtherField2 bit null,
)
insert into temp_owners values
(1, '456 8th st', 45678, 'US', 'c.csv', 'Mike', NULL, NULL),
(2, '678 9th st', 45678, 'US', 'b.csv', 'John', NULL, NULL),
(3, '890 10th st', 45678, 'US', 'b.csv', 'Alex', NULL, NULL),
(4, '901 11th st', 23456, 'US', 'b.csv', 'Alex', NULL, NULL),
(5, '234 5th st', 12345, 'US', 'b.csv', 'John', NULL, NULL),
(6, '123 5th st', 45678, 'US', 'a.csv', 'John', NULL, NULL)
编辑:我收到了很多好的建议和回复,非常感谢。我已经测试了许多解决方案,它们中的许多都对我很有效。不幸的是,我只能奖励一个最佳解决方案。
Z,N,D的“Zip,Name,Document”上与可能性Z,-,D和-,-,D进行匹配; 应该返回两行吗?(三列没有匹配项,最后两列没有匹配项,最后一列有两个匹配项。)还是应该只返回Z,-,D,因为它比-,-,D更匹配? - MatBailie