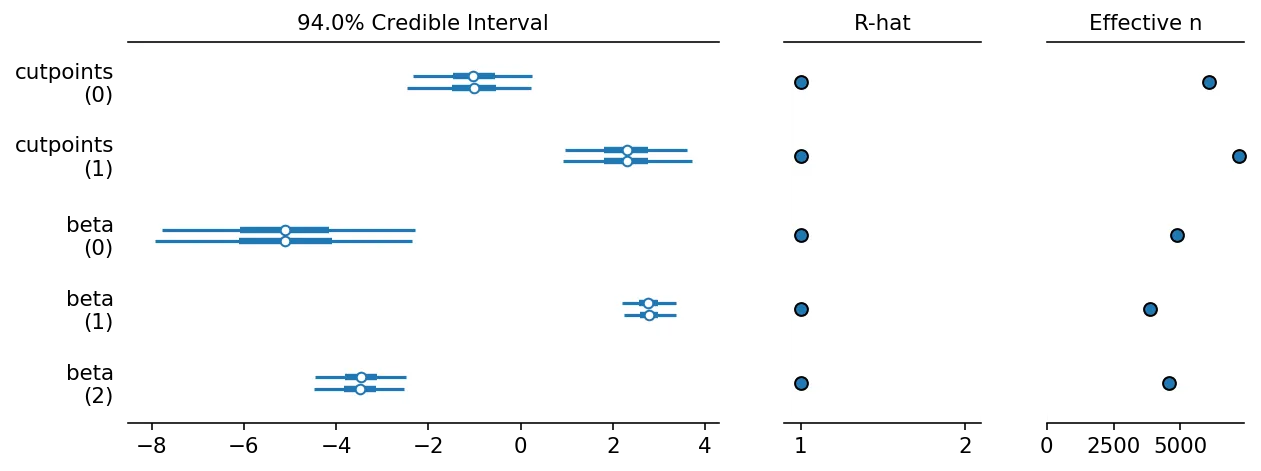
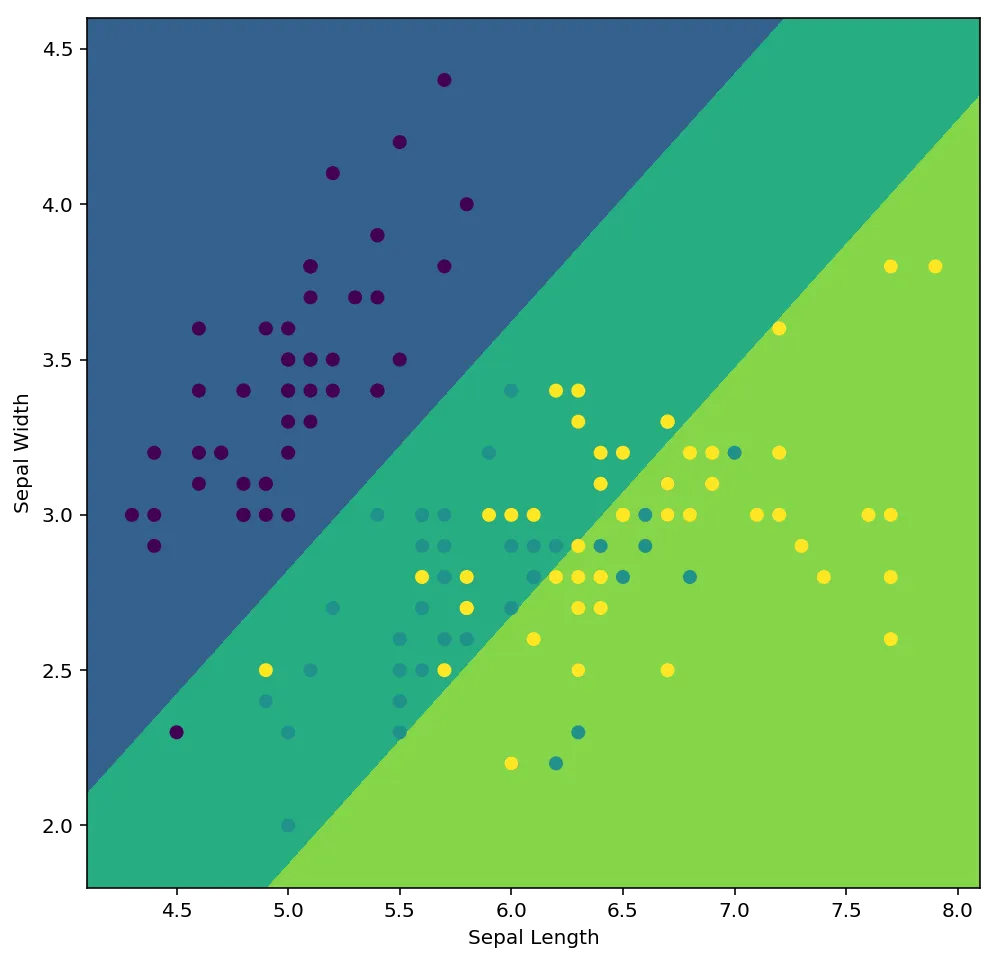
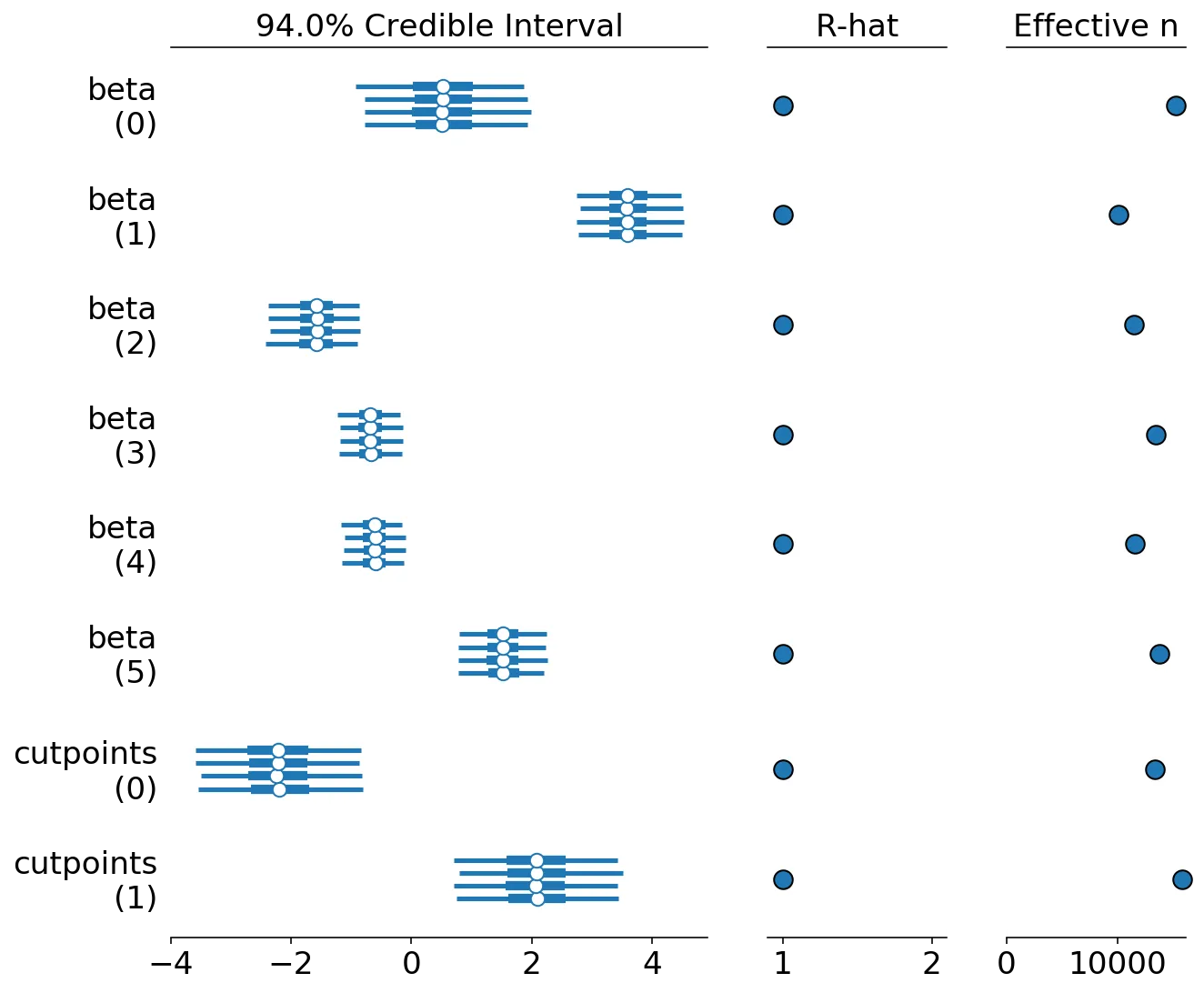
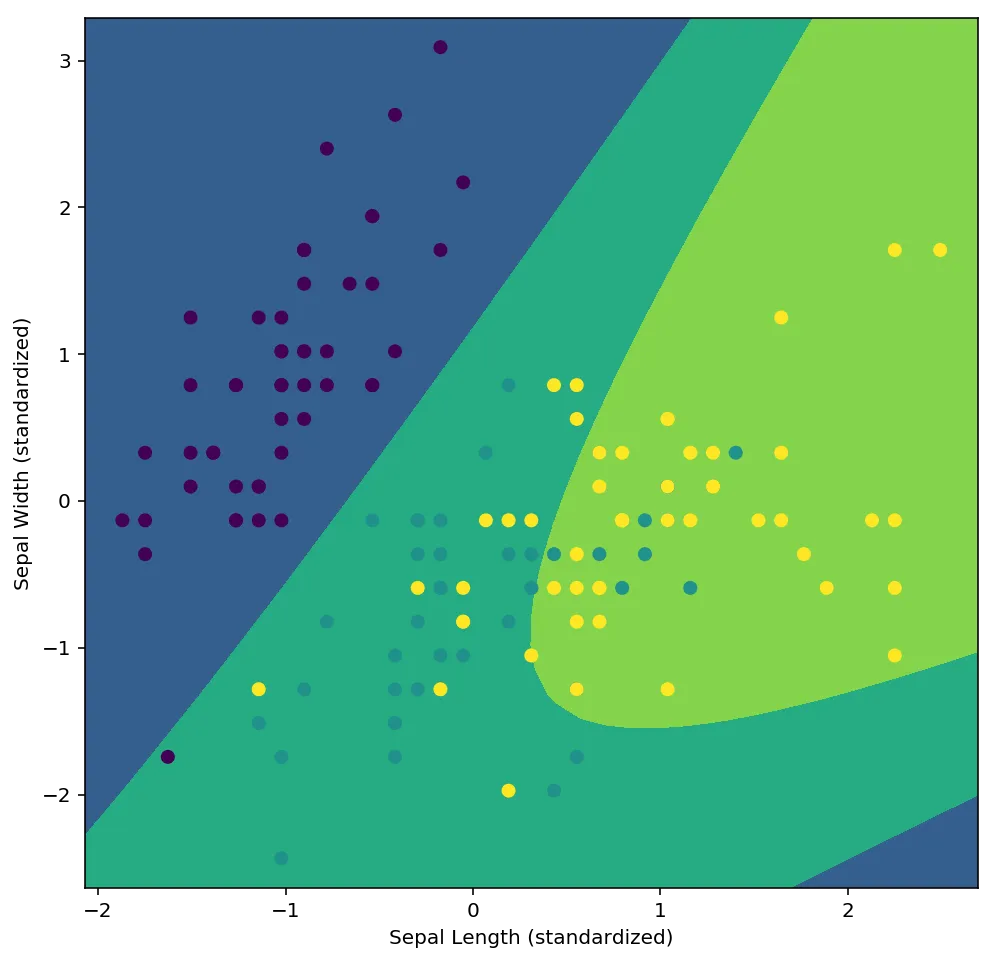
我正在尝试使用PyMC3构建Bayesian多元有序logit模型。我已经成功地基于这本书中的示例创建了一个玩具多元logit模型。我也已经根据此页面底部的示例实现了有序逻辑回归模型。
但是,我无法运行有序的多元逻辑回归。我认为问题可能在于切点的指定方式,具体来说是形状参数,但我不确定为什么如果有多个独立变量就会与只有一个变量时有所不同,因为响应类别的数量并没有改变。
以下是我的代码:
MWE的数据准备:
我收到的错误消息是:“ValueError: all the input array dimensions except for the concatenation axis must match exactly.” 这表明这是一个数据问题(x, y),但数据看起来与多元逻辑回归相同,后者可以正常运行。
如何修复有序多元逻辑回归以使其正常运行?
但是,我无法运行有序的多元逻辑回归。我认为问题可能在于切点的指定方式,具体来说是形状参数,但我不确定为什么如果有多个独立变量就会与只有一个变量时有所不同,因为响应类别的数量并没有改变。
以下是我的代码:
MWE的数据准备:
import pymc3 as pm
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris(return_X_y=False)
iris = pd.DataFrame(data=np.c_[iris['data'], iris['target']],
columns=iris['feature_names'] + ['target'])
iris = iris.rename(index=str, columns={'sepal length (cm)': 'sepal_length', 'sepal width (cm)': 'sepal_width', 'target': 'species'})
这是一个可用的多元(二元)逻辑回归:
df = iris.loc[iris['species'].isin([0, 1])]
y = pd.Categorical(df['species']).codes
x = df[['sepal_length', 'sepal_width']].values
with pm.Model() as model_1:
alpha = pm.Normal('alpha', mu=0, sd=10)
beta = pm.Normal('beta', mu=0, sd=2, shape=x.shape[1])
mu = alpha + pm.math.dot(x, beta)
theta = 1 / (1 + pm.math.exp(-mu))
y_ = pm.Bernoulli('yl', p=theta, observed=y)
trace_1 = pm.sample(5000)
下面是一个使用有序logit回归(只含有一个自变量)的有效示例:
x = iris['sepal_length'].values
y = pd.Categorical(iris['species']).codes
with pm.Model() as model:
cutpoints = pm.Normal("cutpoints", mu=[-2,2], sd=10, shape=2,
transform=pm.distributions.transforms.ordered)
y_ = pm.OrderedLogistic("y", cutpoints=cutpoints, eta=x, observed=y)
tr = pm.sample(1000)
这是我尝试实现的多元有序Logit模型,它可以分解:
x = iris[['sepal_length', 'sepal_width']].values
y = pd.Categorical(iris['species']).codes
with pm.Model() as model:
cutpoints = pm.Normal("cutpoints", mu=[-2,2], sd=10, shape=2,
transform=pm.distributions.transforms.ordered)
y_ = pm.OrderedLogistic("y", cutpoints=cutpoints, eta=x, observed=y)
tr = pm.sample(1000)
我收到的错误消息是:“ValueError: all the input array dimensions except for the concatenation axis must match exactly.” 这表明这是一个数据问题(x, y),但数据看起来与多元逻辑回归相同,后者可以正常运行。
如何修复有序多元逻辑回归以使其正常运行?