使用查找和替换,要删除类似以下内容的标签,应使用什么正则表达式:
``````
注意: ```
``````
注意: ```
这个方法适用于 Notepad++ 5.8.6 (UNICODE)
查找: <option value="\d+">(.*?)</option>
替换: $1
记得选择 "正则表达式" 和 ". 匹配换行符"
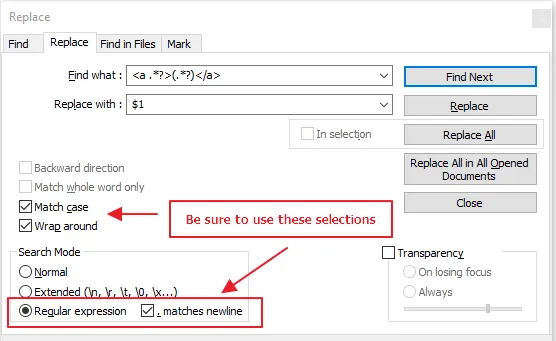
我使用以下正则表达式进行了操作:
查找:<.*?>|</.*?>
并将其替换为:
替换为:\r\n (这是用于换行的)
使用此正则表达式(<.*?>|</.*?>),我们可以轻松地找到您的HTML标记之间的值,如下所示:

我进行了输入:
<otpion value="123">1</option><otpion value="1234">2</option><otpion value="1235">3</option><otpion value="1236">4</option><otpion value="1237">5</option>
我需要在1、2、3、4、5等选项之间找到值。

并得到以下输出:
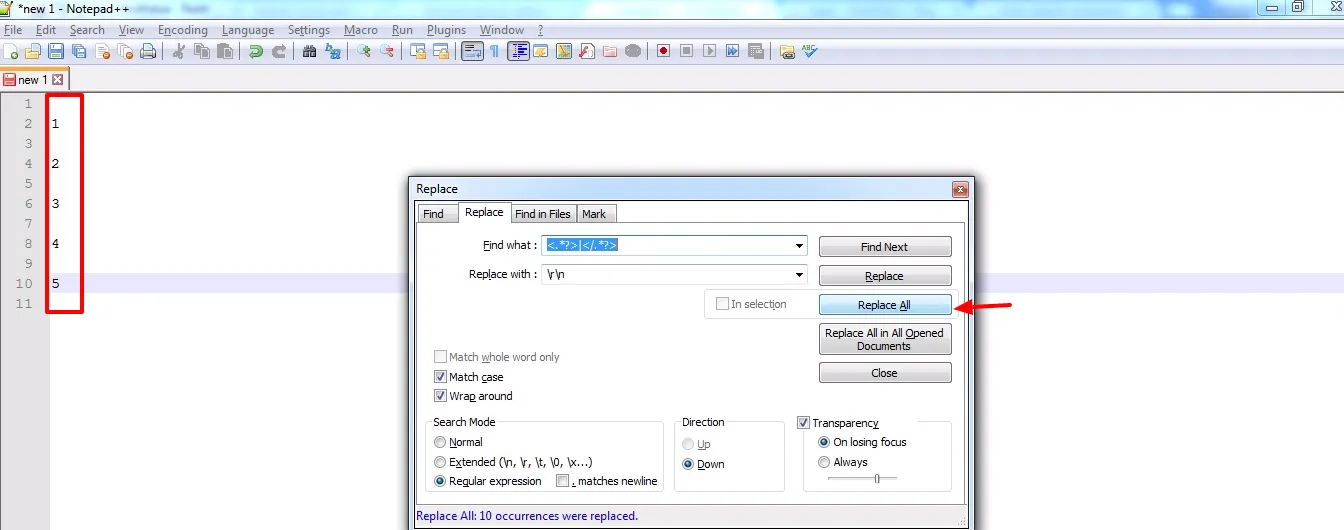
这对我来说完美地运作:
如果您知道HTML的格式不会改变,那么这样的方法就可以使用:
<option value="(\d+)">(.+)</option>
String s = "<option value=\"863\">Viticulture and Enology</option>";
s.replaceAll ("(<option value=\"[0-9]+\">)([^<]+)</option>", "$2")
res1: java.lang.String = Viticulture and Enology
(已使用Scala测试,因此res1:)
使用sed时,您将使用稍微不同的语法:
echo '<option value="863">Viticulture and Enology</option>'|sed -re 's|(<option value="[0-9]+">)([^<]+)</option>|\2|'
对于记事本++,我不知道具体细节,但是"[0-9]+"应该表示“至少一个数字”,“[^<]”表示除了开头的小于号之外的任何字符,可以多次出现。掩码和反向引用可能会有所不同。
正则表达式存在问题,如果跨越多行或被注释隐藏,正则表达式将无法识别它。
然而,很多HTML以正则表达式友好的方式生成,总是适合一行,并且从未被注释掉。或者您在使用一次性代码时,可以在检查输入之前使用它。