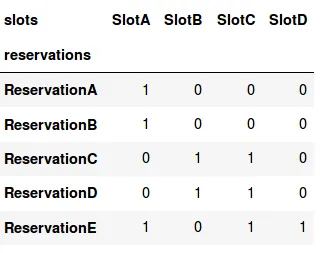
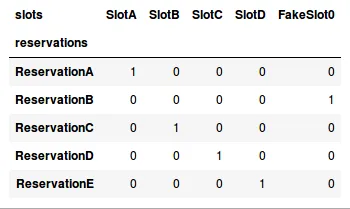
这是一个关于相对复杂问题的算法问题。其基础如下:
基于 可用时间段 和 预订时间段 的排班系统。时间段具有某些标准,我们称之为标签。如果可用时间段的标签集是预订时间段的超集,则预订将与可用时间段匹配。
以具体情况为例,考虑以下场景:
11:00 12:00 13:00
+--------+
| A, B |
+--------+
+--------+
| C, D |
+--------+
A和B,12:00到13:30提供C和D,大约在12:00到12:30之间有重叠。11:00 12:00 13:00
+--------+
| A, B |
+--------+
+--------+
| C, D |
+--------+
xxxxxx
x A x
xxxxxx
这里已经为 A 进行了预订,因此在 11:15-ish 至 12:00-ish 之间不能进行其他 A 或 B 的预订。
简而言之,没有可用时段的具体限制:
- 可用时段可以包含任意数量的标签
- 任意数量的时段可以重叠在任何时间
- 时段长度是任意的
- 预订可以包含任意数量的标签
该系统中唯一需要遵守的规则是:
- 添加预订时,至少有一个剩余的可用时段必须与预订中的所有标签匹配
为了澄清:当同时存在两个带有标签A的可用时段时,在那个时间可以进行两个A的预订,但不能再多了。
我已经使用修改过的区间树实现了这个功能; 简单概述如下:
- 所有可用时段都添加到区间树中(重复/重叠保留)
- 遍历所有已预定的时段并:
- 从树中查询与预订时间匹配的所有可用时段
- 切割其中与预订标签匹配的第一个时段,并将该切片从树中删除
该过程结束后,剩下的是可用时段的剩余切片,我可以查询特定时间是否可以进行新的预订并添加它。
数据结构看起来像这样:
{
type: 'available',
begin: 1497857244,
end: 1497858244,
tags: [{ foo: 'bar' }, { baz: 42 }]
}
{
type: 'reserved',
begin: 1497857345,
end: 1497857210,
tags: [{ foo: 'bar' }]
}
标签本身就是键值对象,它们的列表称为“标签集”。如果有帮助可以对它们进行序列化;到目前为止我使用的是Python set类型,这使得比较非常容易。时间槽的开始/结束时间是树内的UNIX时间戳。我不特别依赖这些具体的数据结构,如果有用的话可以重构。
我面临的问题是,这并不是完全无错的;每隔一段时间会有一个预订会偷偷溜进系统,与其他预订发生冲突,我还不能确定它究竟是如何发生的。当标记以复杂的方式重叠时,最佳分配需要计算,以使所有预订尽可能适合可用插槽;实际上,目前在重叠情况下,预订如何匹配可用插槽是不确定性的。
必须支持的操作:
- 查询满足特定标签集的可用插槽(考虑到可能会减少可用性但本身不属于该标签集的预订;例如,在上面的示例中查询
B的可用性)。 - 确保不能将没有匹配的可用插槽的预订添加到系统中。