我正在努力优化一个程序,该程序依赖于
基本上,我的代码是一篇旧论文代码的翻译,这篇论文使用Matlab和C编写。虽然我没有测量过,但那个代码每秒可以运行多次迭代。而我的代码每次迭代需要几分钟...
这个代码可以在这个存储库中找到:
ad的conjugateGradientDescent函数来完成大部分工作。基本上,我的代码是一篇旧论文代码的翻译,这篇论文使用Matlab和C编写。虽然我没有测量过,但那个代码每秒可以运行多次迭代。而我的代码每次迭代需要几分钟...
这个代码可以在这个存储库中找到:
可以通过以下命令运行相关代码:
$ cd aer-utils
$ cabal sandbox init
$ cabal sandbox add-source ../aer
$ cabal run learngabors
使用 GHC 的性能分析功能,我确认下降过程实际上是花费大部分时间的部分:
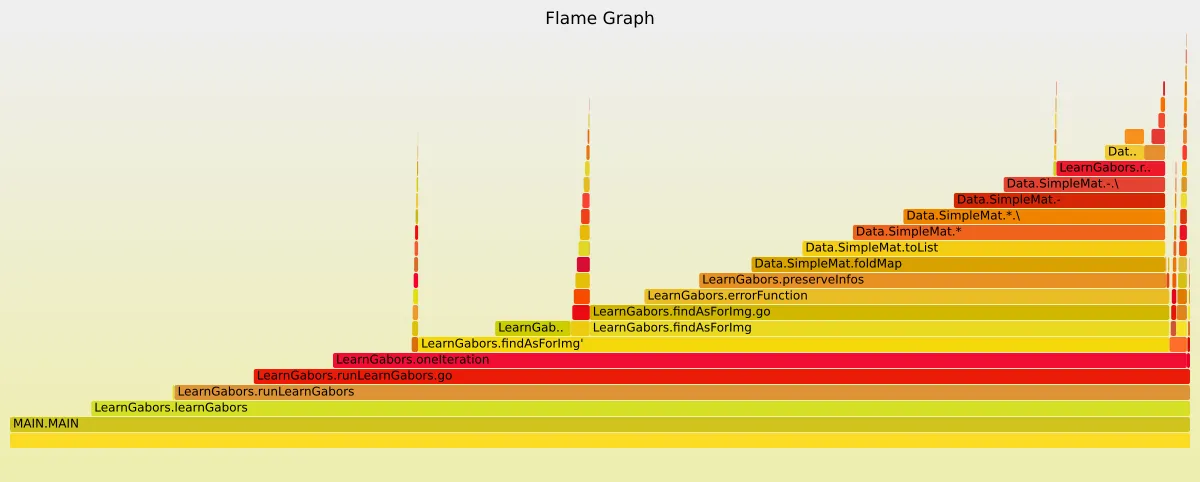
(交互式版本在这里:https://dl.dropboxusercontent.com/u/2359191/learngabors.svg)
{kind=link}
-s 告诉我生产力相当低:
Productivity 33.6% of total user, 33.6% of total elapsed
根据我所了解的,有两个因素可能导致更高的性能:
拆箱: 目前我使用自定义矩阵实现(在
src/Data/SimpleMat.hs中)。这是我能够使ad与矩阵一起工作的唯一方法(参见:如何在hmatrix上进行自动微分?)。我猜想,通过使用像newtype Mat w h a = Mat (Unboxed.Vector a)这样的矩阵类型,由于拆箱和融合,可以实现更好的性能。我发现一些代码具有未装箱向量的ad实例,但到目前为止,我还没有能够将其与conjugateGradientFunction一起使用。矩阵导数: 在一封我现在无法找到的电子邮件中,爱德华提到最好使用矩阵类型的
Forward实例,而不是用Forward实例填充矩阵。我有一个模糊的想法如何实现它,但还没有弄清楚如何在ad的类型类方面实现它。
这可能是一个太广泛的问题,无法在SO上得到答案,如果你愿意帮我解决这个问题,请随时在Github上联系我。
cabal run会运行已编译的代码。从 GHCi 中运行相同的内容(即使用:main)会更慢。 - fho