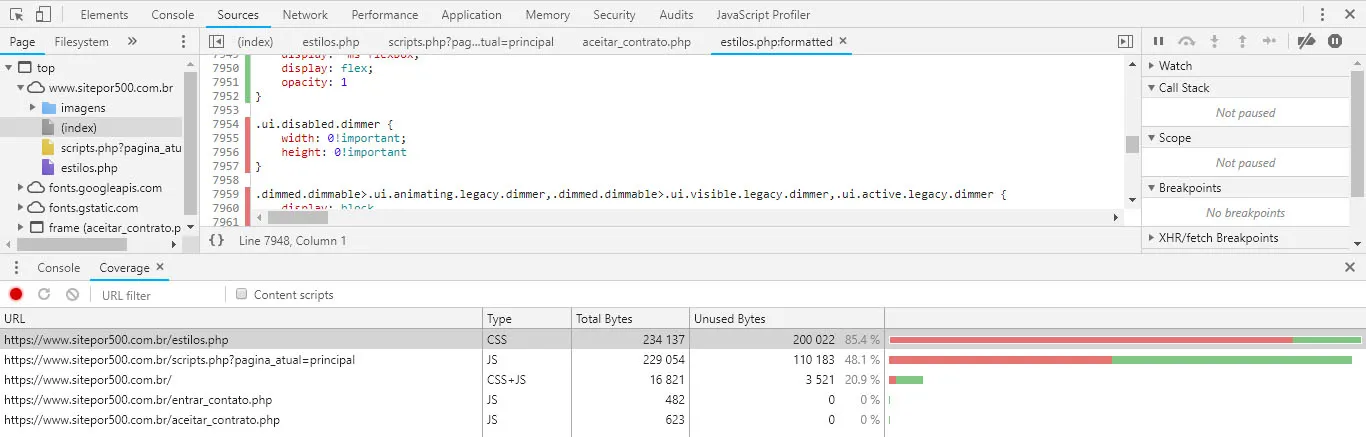
我正在使用Chrome Dev Tools的Coverage选项卡,我有一个非常大的文件,在使用Coverage进行模拟按钮按下、悬停菜单等操作后,清楚地发现只有15%的CSS代码被使用。
问题是如何将这15%的代码从Coverage中取出。我不敢相信这个非常好的功能背后的开发人员没有考虑到一种简单的方法让最终用户仅复制代码中绿色部分。请参见附图。
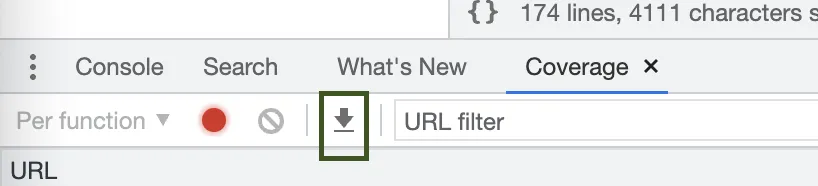
你有任何想法吗?我读到了一些关于使用Puppeteers的内容,但需要做很多准备工作。在最新的Canary版本中,似乎可以导出JSON,但需要编写解析器才能提取所需部分。
问题是如何将这15%的代码从Coverage中取出。我不敢相信这个非常好的功能背后的开发人员没有考虑到一种简单的方法让最终用户仅复制代码中绿色部分。请参见附图。
你有任何想法吗?我读到了一些关于使用Puppeteers的内容,但需要做很多准备工作。在最新的Canary版本中,似乎可以导出JSON,但需要编写解析器才能提取所需部分。