这篇文章包括以下内容:
- 使用包装类覆盖
realloc 和 mremap,以提供重新分配功能。
- 自定义向量类。
- 性能测试。
#include <benchmark/benchmark.h>
#include <new>
#include <memory>
#include <cstdlib>
#include <cstddef>
#include <cassert>
#include <utility>
namespace linux {
#include <sys/mman.h>
#include <errno.h>
auto get_errno() noexcept {
return errno;
}
}
template <class T>
struct mrealloc {
using pointer = T*;
using value_type = T;
auto allocate(std::size_t len) {
if (auto ret = std::malloc(len))
return static_cast<pointer>(ret);
else
throw std::bad_alloc();
}
auto reallocate(pointer old_ptr, std::size_t old_len, std::size_t len) {
if (auto ret = std::realloc(old_ptr, len))
return static_cast<pointer>(ret);
else
throw std::bad_alloc();
}
void deallocate(void *ptr, std::size_t len) noexcept {
std::free(ptr);
}
};
template <class T>
struct mmaprealloc {
using pointer = T*;
using value_type = T;
auto allocate(std::size_t len) const
{
return allocate_impl(len, MAP_PRIVATE | MAP_ANONYMOUS);
}
auto reallocate(pointer old_ptr, std::size_t old_len, std::size_t len) const
{
return reallocate_impl(old_ptr, old_len, len, MREMAP_MAYMOVE);
}
void deallocate(pointer ptr, std::size_t len) const noexcept
{
assert(linux::munmap(ptr, len) == 0);
}
protected:
auto allocate_impl(std::size_t _len, int flags) const
{
if (auto ret = linux::mmap(nullptr, get_proper_size(_len), PROT_READ | PROT_WRITE, flags, -1, 0))
return static_cast<pointer>(ret);
else
fail(EAGAIN | ENOMEM);
}
auto reallocate_impl(pointer old_ptr, std::size_t old_len, std::size_t _len, int flags) const
{
if (auto ret = linux::mremap(old_ptr, old_len, get_proper_size(_len), flags))
return static_cast<pointer>(ret);
else
fail(EAGAIN | ENOMEM);
}
static inline constexpr const std::size_t magic_num = 4096 - 1;
static inline auto get_proper_size(std::size_t len) noexcept -> std::size_t {
return round_to_pagesize(len);
}
static inline auto round_to_pagesize(std::size_t len) noexcept -> std::size_t {
return (len + magic_num) & ~magic_num;
}
static inline void fail(int assert_val)
{
auto _errno = linux::get_errno();
assert(_errno == assert_val);
throw std::bad_alloc();
}
};
template <class T>
struct mmaprealloc_populate_ver: mmaprealloc<T> {
auto allocate(size_t len) const
{
return mmaprealloc<T>::allocate_impl(len, MAP_PRIVATE | MAP_ANONYMOUS | MAP_POPULATE);
}
};
namespace impl {
struct disambiguation_t2 {};
struct disambiguation_t1 {
constexpr operator disambiguation_t2() const noexcept { return {}; }
};
template <class Alloc>
static constexpr auto has_reallocate(disambiguation_t1) noexcept -> decltype(&Alloc::reallocate, bool{}) { return true; }
template <class Alloc>
static constexpr bool has_reallocate(disambiguation_t2) noexcept { return false; }
template <class Alloc>
static inline constexpr const bool has_reallocate_v = has_reallocate<Alloc>(disambiguation_t1{});
}
template <class Alloc>
struct allocator_traits: public std::allocator_traits<Alloc> {
using Base = std::allocator_traits<Alloc>;
using value_type = typename Base::value_type;
using pointer = typename Base::pointer;
using size_t = typename Base::size_type;
static auto reallocate(Alloc &alloc, pointer prev_ptr, size_t prev_len, size_t new_len) {
if constexpr(impl::has_reallocate_v<Alloc>)
return alloc.reallocate(prev_ptr, prev_len, new_len);
else {
auto new_ptr = Base::allocate(alloc, new_len);
for(auto _prev_ptr = prev_ptr, _new_ptr = new_ptr; _prev_ptr != prev_ptr + prev_len; ++_prev_ptr, ++_new_ptr) {
new (_new_ptr) value_type(std::move(*_prev_ptr));
_new_ptr->~value_type();
}
Base::deallocate(alloc, prev_ptr, prev_len);
return new_ptr;
}
}
};
template <class T, class Alloc = std::allocator<T>>
struct vector: protected Alloc {
using alloc_traits = allocator_traits<Alloc>;
using pointer = typename alloc_traits::pointer;
using size_t = typename alloc_traits::size_type;
pointer ptr = nullptr;
size_t last = 0;
size_t avail = 0;
~vector() noexcept {
alloc_traits::deallocate(*this, ptr, avail);
}
template <class ...Args>
void emplace_back(Args &&...args) {
if (last == avail)
double_the_size();
alloc_traits::construct(*this, &ptr[last++], std::forward<Args>(args)...);
}
void double_the_size() {
if (__builtin_expect(!!(avail), true)) {
avail <<= 1;
ptr = alloc_traits::reallocate(*this, ptr, last, avail);
} else {
avail = 1 << 4;
ptr = alloc_traits::allocate(*this, avail);
}
}
};
template <class T>
static void BM_vector(benchmark::State &state) {
for(auto _: state) {
T c;
for(auto i = state.range(0); --i >= 0; )
c.emplace_back((char)i);
}
}
static constexpr const auto one_GB = 1 << 30;
BENCHMARK_TEMPLATE(BM_vector, vector<char>) ->Range(1 << 3, one_GB);
BENCHMARK_TEMPLATE(BM_vector, vector<char, mrealloc<char>>) ->Range(1 << 3, one_GB);
BENCHMARK_TEMPLATE(BM_vector, vector<char, mmaprealloc<char>>) ->Range(1 << 3, one_GB);
BENCHMARK_TEMPLATE(BM_vector, vector<char, mmaprealloc_populate_ver<char>>)->Range(1 << 3, one_GB);
BENCHMARK_MAIN();
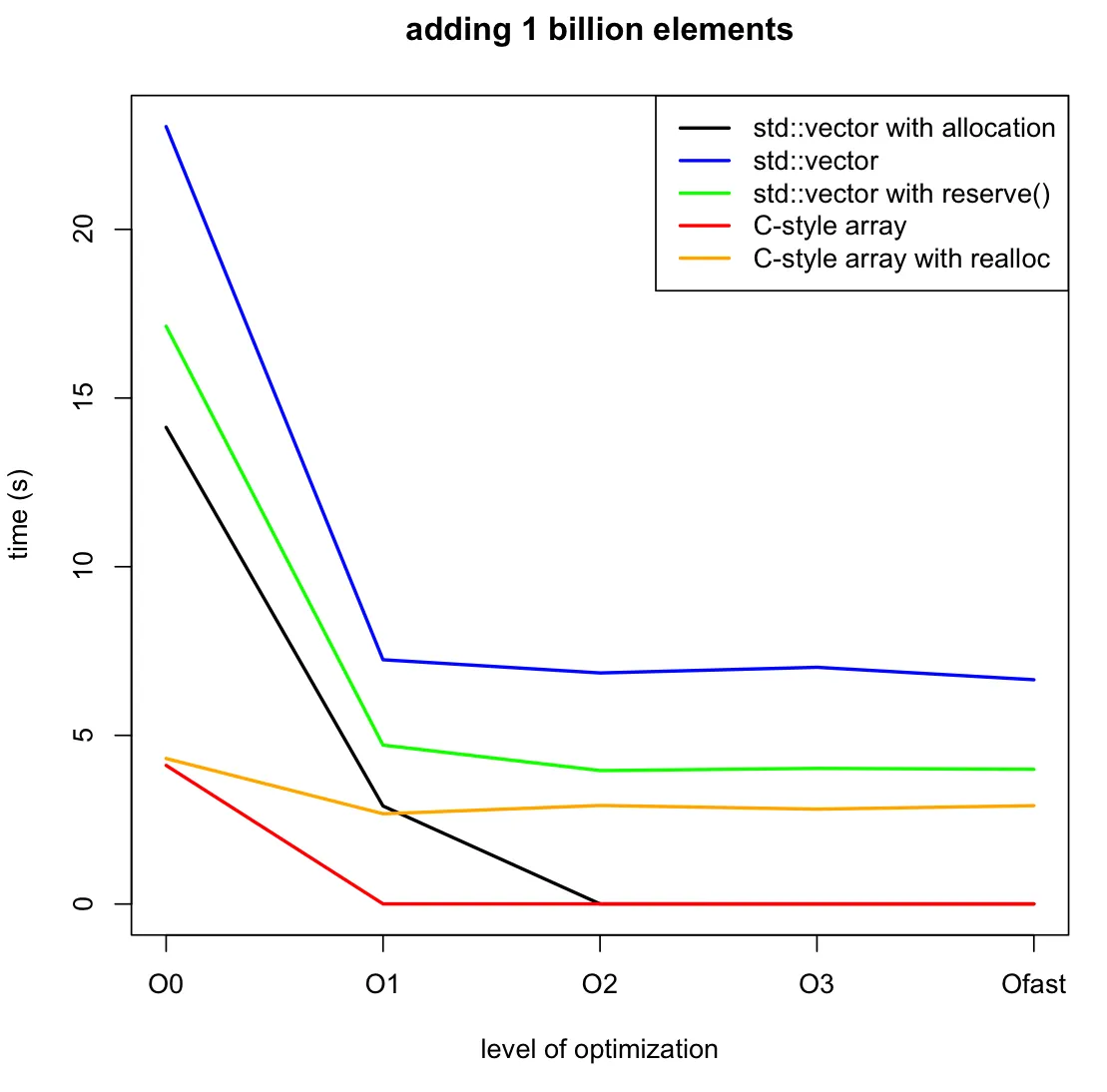
- Performance test.
All the performance test are done on:
Debian 9.4, Linux version 4.9.0-6-amd64 (debian-kernel@lists.debian.org)(gcc version 6.3.0 20170516 (Debian 6.3.0-18+deb9u1) )
Compiled using clang++ -std=c++17 -lbenchmark -lpthread -Ofast main.cc
The command I used to run this test:
sudo cpupower frequency-set --governor performance
./a.out
Here's the output of google benchmark test:
Run on (8 X 1600 MHz CPU s)
CPU Caches:
L1 Data 32K (x4)
L1 Instruction 32K (x4)
L2 Unified 256K (x4)
L3 Unified 6144K (x1)
----------------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations
----------------------------------------------------------------------------------------------------------
BM_vector<vector<char>>/8 58 ns 58 ns 11476934
BM_vector<vector<char>>/64 324 ns 324 ns 2225396
BM_vector<vector<char>>/512 1527 ns 1527 ns 453629
BM_vector<vector<char>>/4096 7196 ns 7196 ns 96695
BM_vector<vector<char>>/32768 50145 ns 50140 ns 13655
BM_vector<vector<char>>/262144 549821 ns 549825 ns 1245
BM_vector<vector<char>>/2097152 5007342 ns 5006393 ns 146
BM_vector<vector<char>>/16777216 42873349 ns 42873462 ns 15
BM_vector<vector<char>>/134217728 336225619 ns 336097218 ns 2
BM_vector<vector<char>>/1073741824 2642934606 ns 2642803281 ns 1
BM_vector<vector<char, mrealloc<char>>>/8 55 ns 55 ns 12914365
BM_vector<vector<char, mrealloc<char>>>/64 266 ns 266 ns 2591225
BM_vector<vector<char, mrealloc<char>>>/512 1229 ns 1229 ns 567505
BM_vector<vector<char, mrealloc<char>>>/4096 6903 ns 6903 ns 102752
BM_vector<vector<char, mrealloc<char>>>/32768 48522 ns 48523 ns 14409
BM_vector<vector<char, mrealloc<char>>>/262144 399470 ns 399368 ns 1783
BM_vector<vector<char, mrealloc<char>>>/2097152 3048578 ns 3048619 ns 229
BM_vector<vector<char, mrealloc<char>>>/16777216 24426934 ns 24421774 ns 29
BM_vector<vector<char, mrealloc<char>>>/134217728 262355961 ns 262357084 ns 3
BM_vector<vector<char, mrealloc<char>>>/1073741824 2092577020 ns 2092317044 ns 1
BM_vector<vector<char, mmaprealloc<char>>>/8 4285 ns 4285 ns 161498
BM_vector<vector<char, mmaprealloc<char>>>/64 5485 ns 5485 ns 125375
BM_vector<vector<char, mmaprealloc<char>>>/512 8571 ns 8569 ns 80345
BM_vector<vector<char, mmaprealloc<char>>>/4096 24248 ns 24248 ns 28655
BM_vector<vector<char, mmaprealloc<char>>>/32768 165021 ns 165011 ns 4421
BM_vector<vector<char, mmaprealloc<char>>>/262144 1177041 ns 1177048 ns 557
BM_vector<vector<char, mmaprealloc<char>>>/2097152 9229860 ns 9230023 ns 74
BM_vector<vector<char, mmaprealloc<char>>>/16777216 75425704 ns 75426431 ns 9
BM_vector<vector<char, mmaprealloc<char>>>/134217728 607661012 ns 607662273 ns 1
BM_vector<vector<char, mmaprealloc<char>>>/1073741824 4871003928 ns 4870588050 ns 1
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/8 3956 ns 3956 ns 175037
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/64 5087 ns 5086 ns 133944
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/512 8662 ns 8662 ns 80579
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/4096 23883 ns 23883 ns 29265
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/32768 158374 ns 158376 ns 4444
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/262144 1171514 ns 1171522 ns 593
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/2097152 9297357 ns 9293770 ns 74
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/16777216 75140789 ns 75141057 ns 9
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/134217728 636359403 ns 636368640 ns 1
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/1073741824 4865103542 ns 4864582150 ns 1
reserve()多少空间,那么如何确定要使用多少new[]? - Bo Perssonb.reserve(size),它基本上与int * a = new int [size];相同。 - NathanOliverrealloc。我猜想在理论上,可以为 POD 类型的默认分配器进行特殊化,但我不认为任何标准库实现会这样做。更公平的比较应该是与malloc、memcpy、free进行比较。 - Justin