我正在尝试从此网站中提取文本“ This station managed by the Delta Flow Projects Office ”:https://waterdata.usgs.gov/ca/nwis/uv?site_no=381504121404001。此行位于
stationContainer类下面。由于这是一个动态网页,我正在使用Selenium来获取HTML。
这是网站上的HTML。
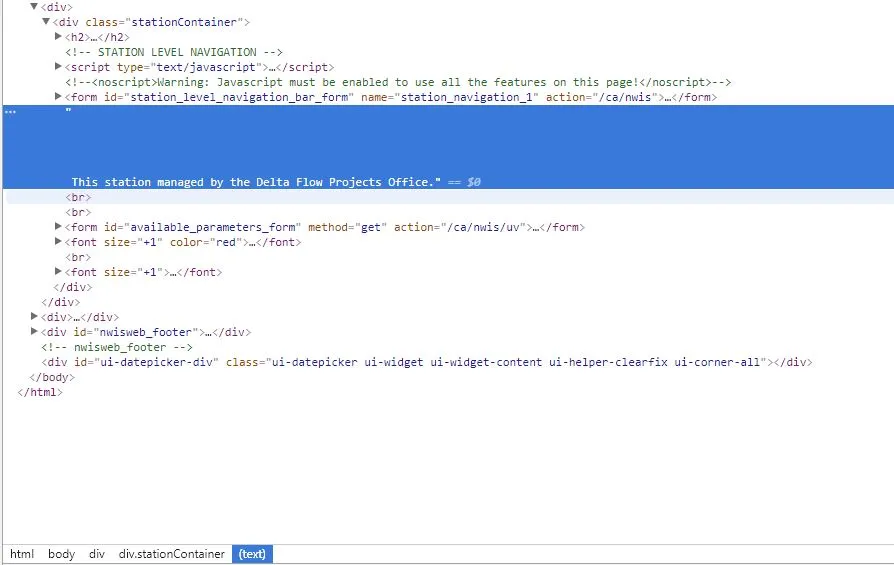
这是我的代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
url = "https://waterdata.usgs.gov/ca/nwis/uv?site_no=381504121404001"
browser.get(url) #navigate to the page
innerHTML = browser.execute_script("return document.body.innerHTML")
elem = browser.find_elements_by_xpath("//div[@class='stationContainer']")
print (elem)
我从我的打印消息中得到了这个结果:
selenium.webdriver.remote.webelement.WebElement (session="96fc124c0e2d1fd4cd86f61db272d52a", element="0.5862443940581294-1")
我希望通过搜索div类来获取文本,但似乎我并没有正确的方法。