我有一个Matlab代码,它非常低效,我需要多次运行它。
该代码基本上是一个大的
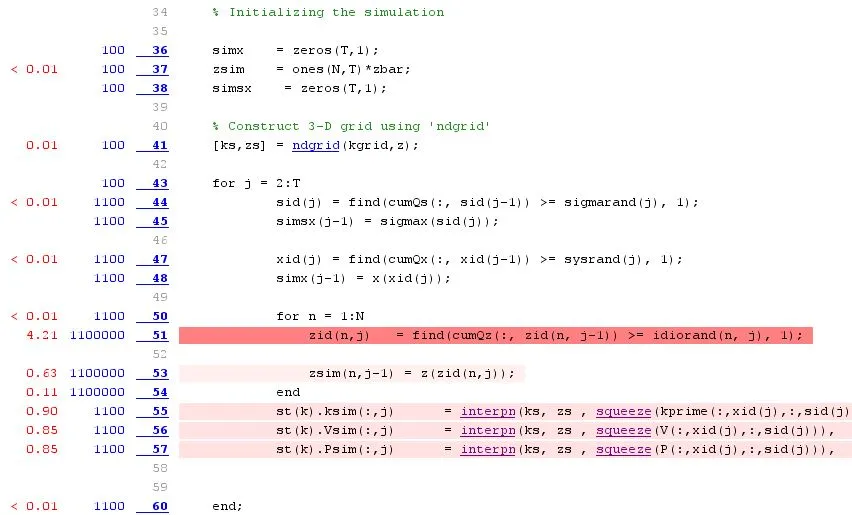
该代码首先加载多个参数和4-D矩阵,然后需要进行几次插值。所有这些都需要重复5000次(因此使用了parfor循环)。
以下是代码的样子。我尽可能简化了代码,但保留了关键部分。
这是运行代码所需矩阵的链接:http://www.filedropper.com/file_406。
有没有更好的方法可以显著减少计算时间?我猜没有......理想情况下,应该有一种向量化k = 1:nsim循环的方法。
parfor循环,我认为几乎不可能绕过它。该代码首先加载多个参数和4-D矩阵,然后需要进行几次插值。所有这些都需要重复5000次(因此使用了parfor循环)。
以下是代码的样子。我尽可能简化了代码,但保留了关键部分。
load file
nsim = 5000
T = 12;
N = 1000;
cumQx = cumsum(Qx);
cumQz = cumsum(Qz);
cumQs = cumsum(Qs);
for k=1:nsim
st(k).ksim = kstar*ones(N, T);
st(k).Vsim = zeros(N,T);
st(k).Psim = zeros(N,T);
end
parfor k = 1:nsim
sysrand = rand(T, 1);
idiorand = rand(N, T);
sigmarand = rand(T,1);
xid = zeros(T, 1);
zid = zeros(N, T);
sid = zeros(T,1);
xid(1) = 8;
zid(:, 1) = 5;
sid(1) = 1;
% Initializing the simulation
simx = zeros(T,1);
zsim = ones(N,T)*zbar;
simsx = zeros(T,1);
% Construct 3-D grid using 'ndgrid'
[ks,zs] = ndgrid(kgrid,z);
for j = 2:T
sid(j) = find(cumQs(:, sid(j-1)) >= sigmarand(j), 1);
simsx(j-1) = sigmax(sid(j));
xid(j) = find(cumQx(:, xid(j-1)) >= sysrand(j), 1);
simx(j-1) = x(xid(j));
for n = 1:N
zid(n, j) = find(cumQz(:, zid(n, j-1)) >= idiorand(n, j), 1);
zsim(n,j-1) = z(zid(n, j));
end
st(k).ksim(:,j) = interpn(ks, zs , squeeze(kprime(:,xid(j),:,sid(j))), st(k).ksim(:,j-1),zsim(:,j-1),'linear'); % K
st(k).Vsim(:,j) = interpn(ks, zs , squeeze(V(:,xid(j),:,sid(j))), st(k).ksim(:,j-1),zsim(:,j-1),'linear'); % V
st(k).Psim(:,j) = interpn(ks, zs , squeeze(P(:,xid(j),:,sid(j))), st(k).ksim(:,j-1),zsim(:,j-1),'linear'); % P
end;
end
这是运行代码所需矩阵的链接:http://www.filedropper.com/file_406。
有没有更好的方法可以显著减少计算时间?我猜没有......理想情况下,应该有一种向量化k = 1:nsim循环的方法。