基本上,我需要能够创建一个Unicode文本文件,但无论我做什么它都会保存为ANSI格式。
以下是我的代码:
以下是我的代码:
wchar_t name[] = L"中國哲學書電子化計劃";
FILE * pFile;
pFile = fopen("chineseLetters.txt", "w");
fwrite(name, sizeof(wchar_t), sizeof(name), pFile);
fclose(pFile);
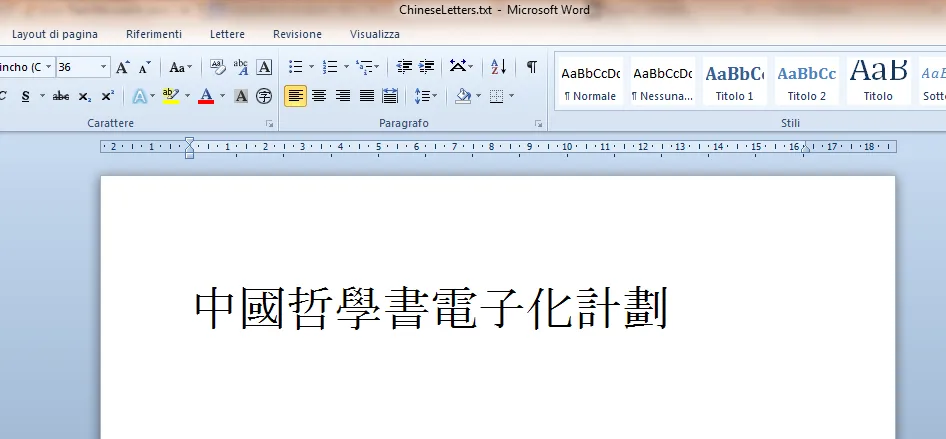
这是我的“chineseLetters.txt”的输出结果:
-NWòTx[øfû–P[SŠƒR õ2123
此外,该应用程序采用MBCS格式,无法改为Unicode,因为它需要与Unicode和ANSI都能正常工作。
我非常希望能得到一些帮助。谢谢。
感谢所有快速回复的人!它有效了!
仅仅添加L"\uFFFE中國哲學書電子化計劃"仍然不起作用,文本编辑器仍将其识别为CP1252,所以我进行了两次fwrite,一次用于BOM,一次用于字符。以下是我的代码:
wchar_t name[] = L"中國哲學書電子化計劃";
unsigned char bom[] = { 0xFF, 0xFE };
FILE * pFile;
pFile = fopen("chineseLetters.txt", "w");
fwrite(bom, sizeof(unsigned char), sizeof(bom), pFile);
fwrite(name, sizeof(wchar_t), wcslen(name), pFile);
fclose(pFile);
frwite()调用应该是:fwrite(name, sizeof(wchar_t), sizeof(name)/sizeof(wchar_t), pFile);。 - Galikchar而不是wchar_t(假设我的修复已经完成),那么对我来说它可以正常工作。 - Galik