在内存中存储数据所需的RAM与在文件中存储相同数据所需的磁盘空间相比如何?是否存在一般化的相关性?
例如,假设我有10亿个浮点值。以二进制形式存储,它将占用4亿字节或3.7GB的磁盘空间(不包括标头等)。然后假设我将这些值读入Python列表中...我应该期望需要多少RAM?
在内存中存储数据所需的RAM与在文件中存储相同数据所需的磁盘空间相比如何?是否存在一般化的相关性?
例如,假设我有10亿个浮点值。以二进制形式存储,它将占用4亿字节或3.7GB的磁盘空间(不包括标头等)。然后假设我将这些值读入Python列表中...我应该期望需要多少RAM?
如果数据存储在某个Python对象中,那么实际数据在内存中会有更多的相关数据。
这很容易进行测试。
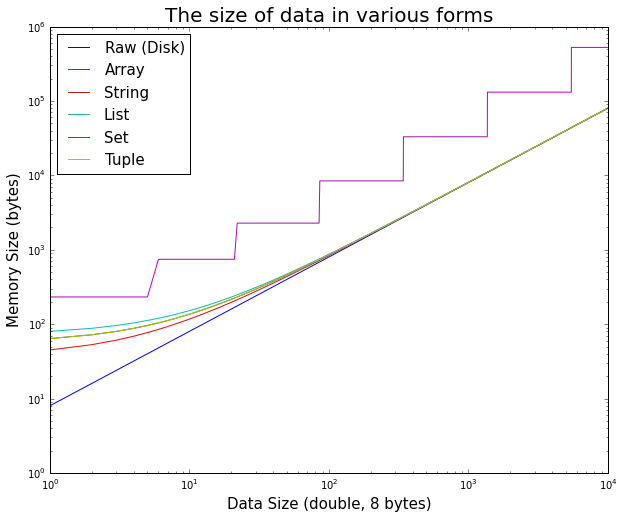
值得注意的是,对于小数据,Python对象的开销非常显著,但很快就变得可以忽略不计。
以下是用于生成图表的iPython代码:
%matplotlib inline
import random
import sys
import array
import matplotlib.pyplot as plt
max_doubles = 10000
raw_size = []
array_size = []
string_size = []
list_size = []
set_size = []
tuple_size = []
size_range = range(max_doubles)
# test double size
for n in size_range:
double_array = array.array('d', [random.random() for _ in xrange(n)])
double_string = double_array.tostring()
double_list = double_array.tolist()
double_set = set(double_list)
double_tuple = tuple(double_list)
raw_size.append(double_array.buffer_info()[1] * double_array.itemsize)
array_size.append(sys.getsizeof(double_array))
string_size.append(sys.getsizeof(double_string))
list_size.append(sys.getsizeof(double_list))
set_size.append(sys.getsizeof(double_set))
tuple_size.append(sys.getsizeof(double_tuple))
# display
plt.figure(figsize=(10,8))
plt.title('The size of data in various forms', fontsize=20)
plt.xlabel('Data Size (double, 8 bytes)', fontsize=15)
plt.ylabel('Memory Size (bytes)', fontsize=15)
plt.loglog(
size_range, raw_size,
size_range, array_size,
size_range, string_size,
size_range, list_size,
size_range, set_size,
size_range, tuple_size
)
plt.legend(['Raw (Disk)', 'Array', 'String', 'List', 'Set', 'Tuple'], fontsize=15, loc='best')
list、set和tuple的报告内存大小增加len(double_list) * sys.getsizeof(1.0)。可能还需要一些额外的内存来管理分配,但我不知道如何测量它,而且应该是可以忽略不计的。 - Jan Špačektypedef struct {
PyObject_HEAD
double ob_fval;
} PyFloatObject;
其中PyObject_HEAD是一个宏,用于扩展到PyObject结构体:
typedef struct _object {
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;
sys.getsizeof(1.0) == 24进行确认。n个双精度数组成的列表需要至少8*n字节的内存来存储指向数字对象的指针(PyObject*),而每个数字对象需要额外的24字节。要测试它,请尝试在Python REPL中运行以下代码:>>> import math
>>> list_of_doubles = [math.sin(x) for x in range(10*1000*1000)]
并查看Python解释器的内存使用情况(在我的x86-64计算机上分配了约350 MB的内存)。请注意,如果您尝试:
>>> list_of_doubles = [1.0 for __ in range(10*1000*1000)]
如果列表中的所有元素都指向浮点数1.0的同一实例,则您将只获得约80 MB。