当我将一个file.csv文件放入S3存储桶时,我的lambda函数出现以下错误。这个文件并不大,我甚至在读取文件之前添加了60秒的休眠时间,但是出现了额外的".6CEdFe7C"附加到文件上的情况。为什么会这样?
[Errno 30] Read-only file system: u'/file.csv.6CEdFe7C': IOError
Traceback (most recent call last):
File "/var/task/lambda_function.py", line 75, in lambda_handler
s3.download_file(bucket, key, filepath)
File "/var/runtime/boto3/s3/inject.py", line 104, in download_file
extra_args=ExtraArgs, callback=Callback)
File "/var/runtime/boto3/s3/transfer.py", line 670, in download_file
extra_args, callback)
File "/var/runtime/boto3/s3/transfer.py", line 685, in _download_file
self._get_object(bucket, key, filename, extra_args, callback)
File "/var/runtime/boto3/s3/transfer.py", line 709, in _get_object
extra_args, callback)
File "/var/runtime/boto3/s3/transfer.py", line 723, in _do_get_object
with self._osutil.open(filename, 'wb') as f:
File "/var/runtime/boto3/s3/transfer.py", line 332, in open
return open(filename, mode)
IOError: [Errno 30] Read-only file system: u'/file.csv.6CEdFe7C'
代码:
def lambda_handler(event, context):
s3_response = {}
counter = 0
event_records = event.get("Records", [])
s3_items = []
for event_record in event_records:
if "s3" in event_record:
bucket = event_record["s3"]["bucket"]["name"]
key = event_record["s3"]["object"]["key"]
filepath = '/' + key
print(bucket)
print(key)
print(filepath)
s3.download_file(bucket, key, filepath)
以上的结果是:
mytestbucket
file.csv
/file.csv
[Errno 30] Read-only file system: u'/file.csv.6CEdFe7C'
如果密钥/文件名为"file.csv",那么为什么s3.download_file方法要尝试下载"file.csv.6CEdFe7C"?我猜测当函数被触发时,文件是file.csv.xxxxx,但到达第75行时,文件被重命名为file.csv了吗?

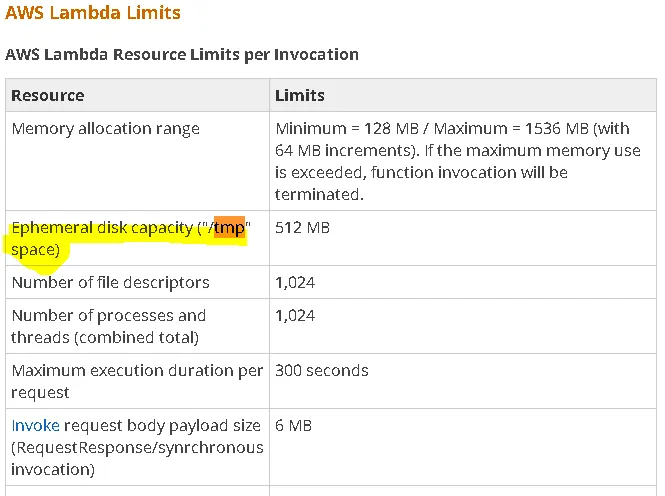
self._osutil.open(filename, 'wb') as f:。只允许使用rb等模式。因此,在处理之前需要处理源文件。 - dsgdfg