我注意到字符串字面值在内存中的地址与其他常量和变量非常不同(Linux操作系统):它们具有许多前导零(未打印)。
例如:
例如:
const char *h = "Hi";
int i = 1;
printf ("%p\n", (void *) h);
printf ("%p\n", (void *) &i);
输出:
0x400634
0x7fffc1ef1a4c
我知道它们存储在可执行文件的 .rodata 部分。操作系统是否有特殊的处理方式,使得这些字面量最终位于内存的特定区域(带有前导零)?这个内存位置有什么优势,还是说有什么特别之处吗?
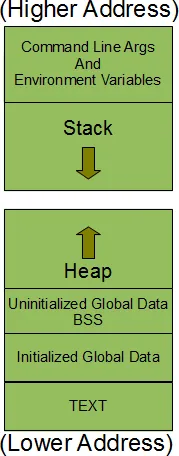
[linux]标记。如果是其他内容,请澄清。 - user694733int i = 1,你可以尝试使用char h[] = "Hi"。 - Hagen von Eitzen