我必须使用这段代码多次循环,有更好的方法吗?
item = '!@#$abc-123-4;5.def)(*&^;\n'
或者
'!@#$abc-123-4;5.def)(*&^;\n_'
或者
'!@#$abc-123-4;5.def)_(*&^;\n_'
我有一个像这样的,但它不起作用
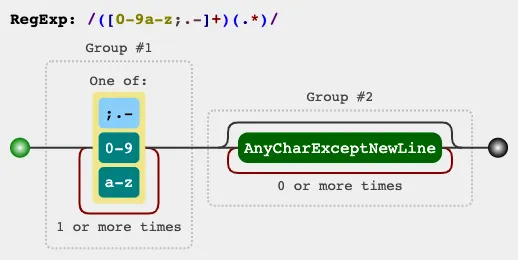
item = re.sub('^\W|\W$', '', item)
期望
abc-123-4;5.def
最终目标是仅保留两端的任何非
[a-zA-Z0-9]字符,同时保留中间的任何字符。第一个和最后一个字母在类[a-zA-Z0-9]中。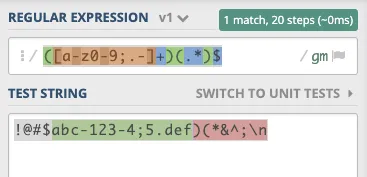
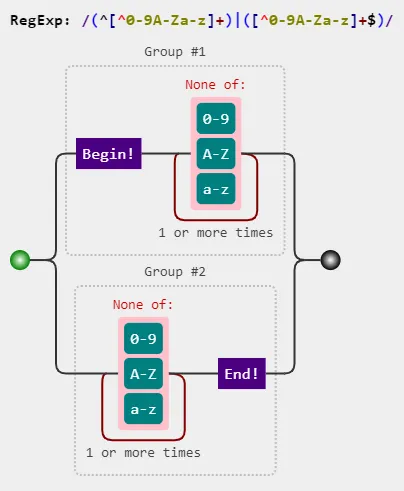
^\W+|\W+$? - CAustin^\W+|\W+$。该正则表达式用于匹配一个字符串开头和结尾处的非单词字符。 - user557597+,我使用了一个递归函数,我以为它应该是错误的,谢谢! - Gang