我公司进行在线消费者行为分析,并使用我们从各个网站收集的数据进行实时预测(使用我们嵌入的Java脚本)。
我们一直在使用AWS ML进行实时预测,但现在我们正在尝试使用AWS SageMaker,我们发现与AWS ML相比,实时数据处理是一个问题。例如,我们有一些字符串变量,AWS ML可以将它们转换为数字,并在AWS ML中自动用于实时预测。但似乎SageMaker无法做到这一点。
有没有人在AWS SageMaker中有实时数据处理和预测方面的经验?
我公司进行在线消费者行为分析,并使用我们从各个网站收集的数据进行实时预测(使用我们嵌入的Java脚本)。
我们一直在使用AWS ML进行实时预测,但现在我们正在尝试使用AWS SageMaker,我们发现与AWS ML相比,实时数据处理是一个问题。例如,我们有一些字符串变量,AWS ML可以将它们转换为数字,并在AWS ML中自动用于实时预测。但似乎SageMaker无法做到这一点。
有没有人在AWS SageMaker中有实时数据处理和预测方面的经验?
听起来你只熟悉SageMaker的培训组件。SageMaker有几个不同的组件:
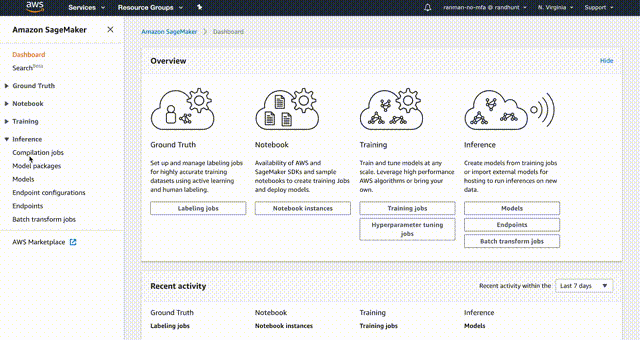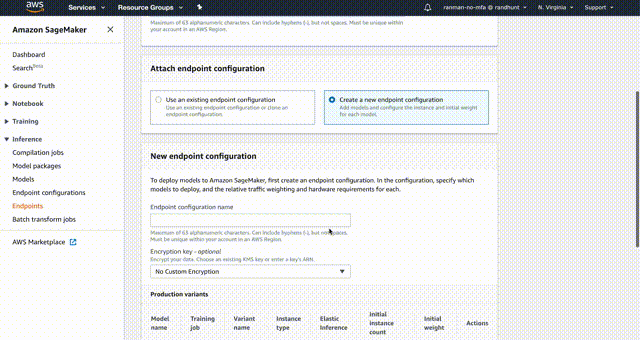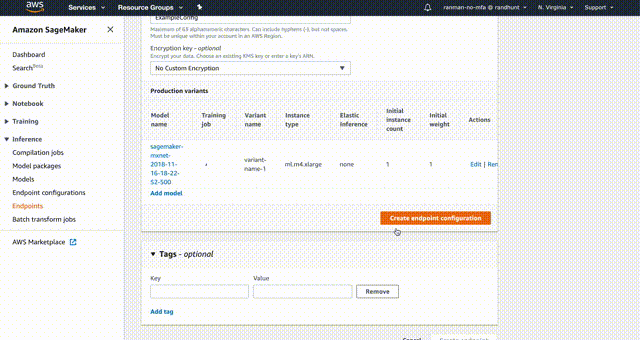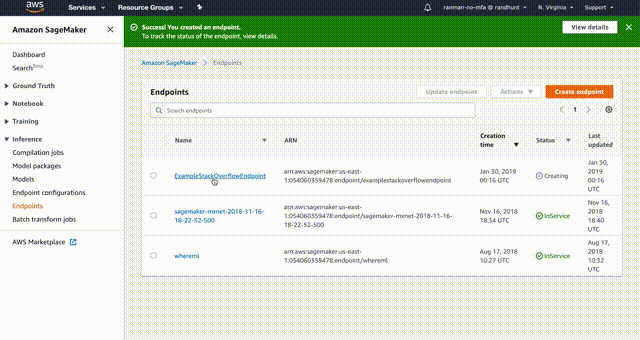
如果您想使用代码实时调用端点,可以使用任何AWS SDK,这里我将演示如何使用Python SDK boto3:
import boto3
sagemaker = boto3.client("runtime.sagemaker")
response = sagemaker.invoke_endpoint(EndpointName="herpderp", Body="some content")
一旦您选择了模型,SageMaker会自动处理数据,并提供一个简单易懂的界面来跟踪您的模型进展和性能。
训练
SageMaker提供了一系列工具来从您准备的数据中训练模型,包括一个内置的调试器,用于检测可能的错误。
机器学习 训练作业的结果保存在Amazon S3存储桶中,可以使用其他AWS服务,包括AWS Quicksight查看.
部署
如果强大的机器学习模型无法轻松部署到您的托管基础设施上,那么它们就毫无意义。幸运的是,SageMaker允许将机器学习模型部署到当前服务和应用程序中,只需单击一下即可完成。
安装后,SageMaker允许进行实时数据处理和预测。这对各种领域都有深远的影响,包括金融和健康。例如,在股票市场运营的企业可能会实时做出关于股票的财务决策,并通过确定购买最佳时间而进行更有吸引力的收购。
与Amazon Comprehend的结合,允许自然语言处理,将人类语音转化为可用数据来训练更好的模型,或通过Amazon Lex向客户提供聊天机器人。
最后…
机器学习不再是一种小众技术好奇心;它现在在全球数千家公司的决策过程中发挥着关键作用。现在开始你的机器学习之旅比以往任何时候都更好,因为几乎有无限的框架,并且可以轻松集成到AWS系统中。