通过使用 PySpark、PostgreSQL 和 Apache Sedona,我学会了用两种方法来解决这个问题。
方法1:下载JAR文件并添加到spark.jars
为了在Spark上使用PostgreSQL,我需要将JDBC驱动程序(JAR文件)添加到PySpark中。
首先,在与我的程序同级别创建一个jars目录,并将postgresql-42.5.0.jar文件存储在其中。
然后,我只需使用以下配置将其添加到SparkSession中:SparkSession.builder.config("spark.jars", "{JAR_FILE_PATH}")
spark = (
SparkSession.builder
.config("spark.jars", "jars/postgresql-42.5.0.jar")
.master("local[*]")
.appName("Example - Add a JAR file")
.getOrCreate()
)
方法二:使用Maven Central坐标和spark.jars.packages
如果您的依赖JAR文件可在Maven上获得,您可以使用此方法,无需维护任何JAR文件。
步骤
在Maven Central Repository Search上找到你的软件包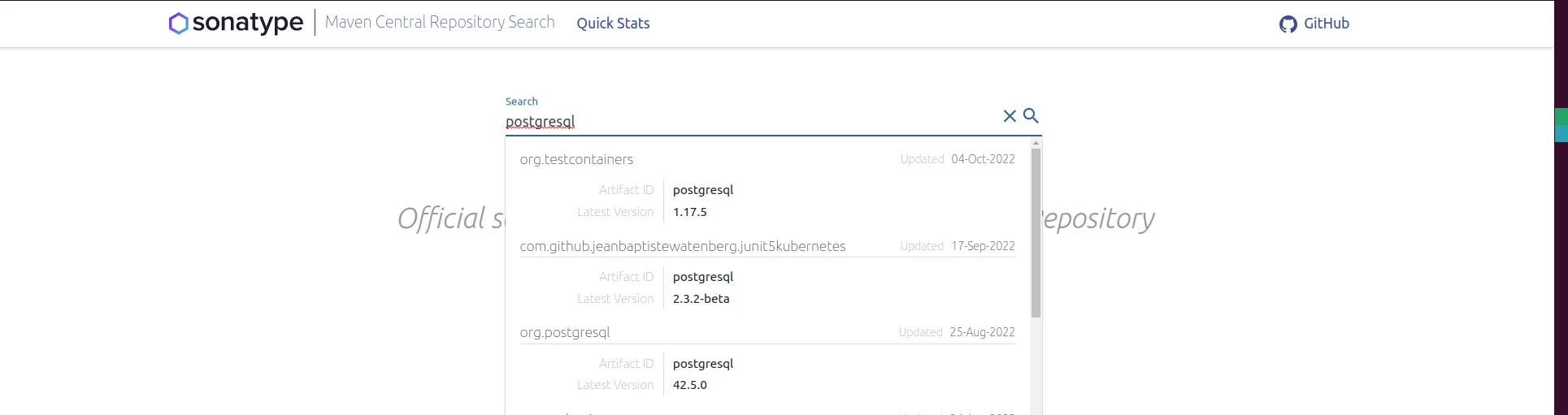
选择正确的软件包构件并复制Maven Central coordinate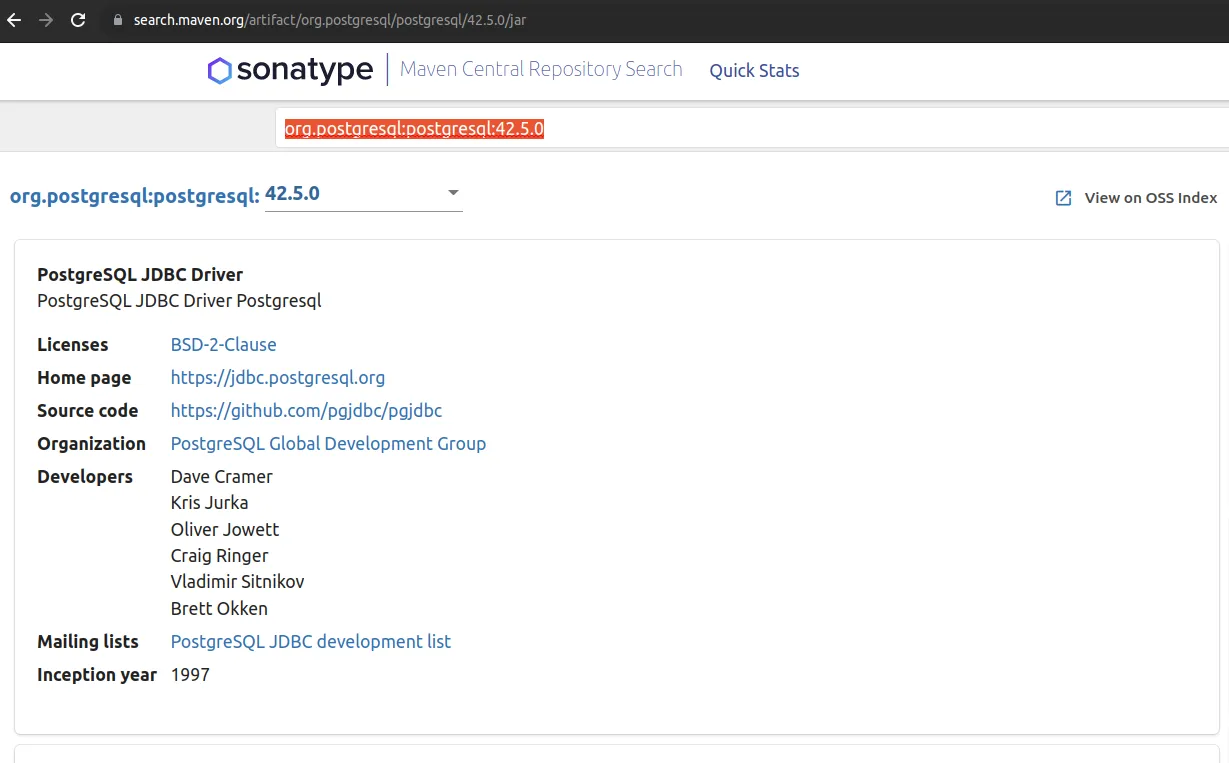
在Python中,调用SparkSession.builder.config("spark.jars.packages", "{MAVEN_CENTRAL_COORDINATE}")。
spark = (
SparkSession.builder
.appName('Example - adding many Maven packages')
.config("spark.serializer", KryoSerializer.getName)
.config("spark.kryo.registrator", SedonaKryoRegistrator.getName)
.config("spark.jars.packages",
"org.postgresql:postgresql:42.5.0,"
+ "org.apache.sedona:sedona-python-adapter-3.0_2.12:1.2.1-incubating,"
+ "org.datasyslab:geotools-wrapper:1.1.0-25.2")
.getOrCreate()
)
使用 sparks.jars.packages 的优点
- 您可以添加多个软件包
- 您无需管理大型 JAR 文件
使用 sparks.jars.packages 的缺点
.config("sparks.jars.packages", ...) 只接受一个参数,因此为了添加多个软件包,您需要使用,作为分隔符连接软件包坐标。
"org.postgresql:postgresql:42.5.0,"
+ "org.apache.sedona:sedona-python-adapter-3.0_2.12:1.2.1-incubating,"
+ "org.datasyslab:geotools-wrapper:1.1.0-25.2"
*** 字符串不容忍您的代码中出现换行、空格或制表符,这将导致严重的错误日志并产生无关紧要的错误。
jar -tvf fileName.jar | grep -i kafka,但没有找到kafka相关的内容。你的在哪里?我不一定对kafka本身感兴趣;我只是在跟随你的示例尝试将其推广。 - NYCeyes