我有一个大约15万个单词的数据库和一个模式(任何单词),我想从数据库中获取所有与该模式的Damerau-Levenshtein距离小于给定数字的单词。我需要非常快速地完成它。您可以建议哪种算法?如果没有好的Damerau-Levenshtein距离算法,那么Levenshtin距离也可以。
谢谢您的帮助。
P.S. 我不打算使用SOUNDEX。
谢谢您的帮助。
P.S. 我不打算使用SOUNDEX。
我认为你不能在不枚举所有行的情况下计算这种函数。
因此,解决方案如下:
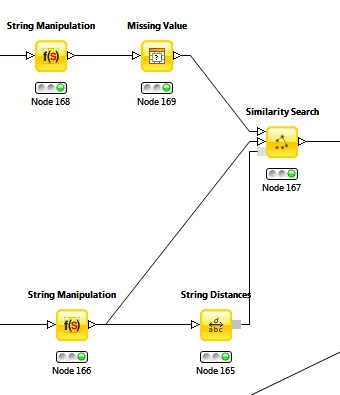
std::set),因为按字典顺序排序的字符串似乎会有很好的比较效果。为了近似给定字符串在set中的位置,可以在字符串上使用std::upper_bound,然后从找到的位置向两个方向迭代集合,计算距离,并在距离低于某个阈值时停止。我有一种感觉,这个解决方案可能只匹配具有相同起始字符的字符串,但如果您正在使用该算法进行拼写检查,则该限制是常见的,或者至少不足为奇。我已经使用KNIME进行了字符串模糊匹配,并获得了非常快速的结果。在其中制作可视化工作流也非常容易。只需从https://www.knime.org/安装KNIME免费版,然后使用"String Distance"和"Similarity Search"节点即可获得您的结果。我在此附上一个小的模糊匹配示例工作流程(在这种情况下,输入数据来自顶部,要搜索的模式来自底部):
我建议你研究一下Ankiro。
我不确定它是否符合你对精度的要求,但它很快。