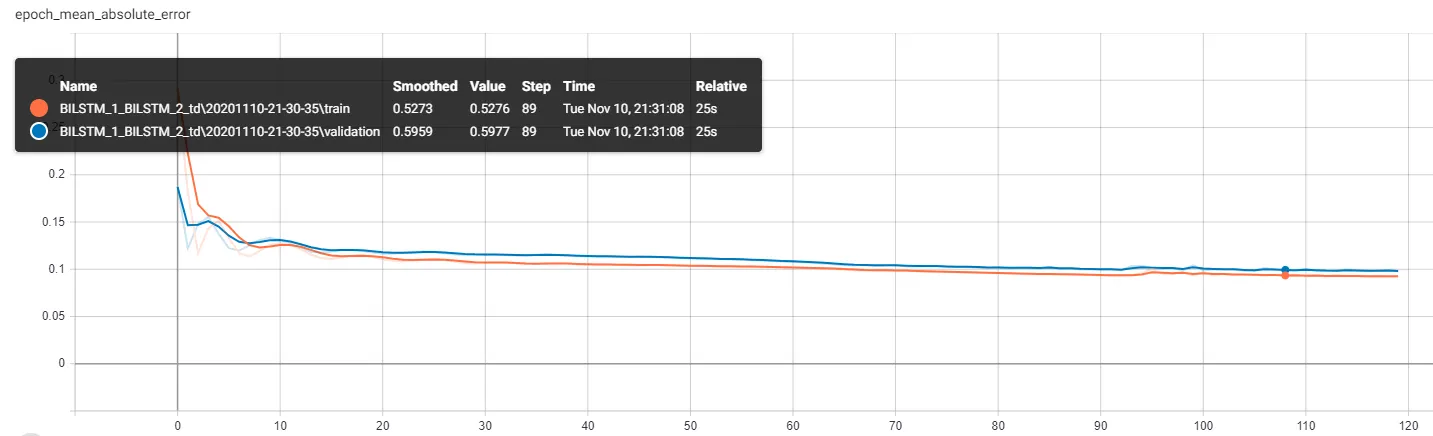
我一直在研究训练集和验证集的损失函数,发现即使是同一数据集,验证损失函数也比训练损失函数小。我希望能够了解为什么会出现这种情况。
我正在使用tensorflow训练一个模型来预测某些时间序列数据。因此,模型创建和预处理如下:
window_size = 40
batch_size = 32
forecast_period = 6
model_name = "LSTM"
tf.keras.backend.clear_session()
_seed = 42
tf.random.set_seed(_seed)
def _sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
def _return_input_output(tensor):
_input = tensor[:, :-forecast_period, :]
_output = tensor[:, forecast_period:, :]
return _input, _output
def _reshape_tensor(tensor):
tensor = tf.expand_dims(tensor, axis=-1)
tensor = tf.transpose(tensor, [1, 0, 2])
return tensor
# total elements after unbatch(): 3813
train_ts_dataset = tf.data.Dataset.from_tensor_slices(train_ts)\
.window(window_size, shift=1)\
.flat_map(_sub_to_batch)\
.map(_reshape_tensor)\
.map(_return_input_output)
# .unbatch().shuffle(buffer_size=500, seed=_seed).batch(batch_size)\
# .map(_return_input_output)
valid_ts_dataset = tf.data.Dataset.from_tensor_slices(valid_ts)\
.window(window_size, shift=1)\
.flat_map(_sub_to_batch)\
.map(_reshape_tensor)\
.unbatch().shuffle(buffer_size=500, seed=_seed).batch(batch_size)\
.map(_return_input_output)
def _forecast_mae(y_pred, y_true):
_y_pred = y_pred[:, -forecast_period:, :]
_y_true = y_true[:, -forecast_period:, :]
mae = tf.losses.MAE(_y_true, _y_pred)
return mae
def _accuracy(y_pred, y_true):
# print(y_true) => Tensor("sequential/time_distributed/Reshape_1:0", shape=(None, 34, 1), dtype=float32)
# y_true[-forecast_period:, :] => Tensor("strided_slice_4:0", shape=(None, 34, 1), dtype=float32)
# y_true[:, -forecast_period:, :] => Tensor("strided_slice_4:0", shape=(None, 6, 1), dtype=float32)
_y_pred = y_pred[:, -forecast_period:, :]
_y_pred = tf.reshape(_y_pred, shape=[-1, forecast_period])
_y_true = y_true[:, -forecast_period:, :]
_y_true = tf.reshape(_y_true, shape=[-1, forecast_period])
# MAPE: Tensor("Mean_1:0", shape=(None, 1), dtype=float32)
MAPE = tf.math.reduce_mean(tf.math.abs((_y_pred - _y_true) / _y_true), axis=1, keepdims=True)
accuracy = 1 - MAPE
accuracy = tf.where(accuracy < 0, tf.zeros_like(accuracy), accuracy)
accuracy = tf.reduce_mean(accuracy)
return accuracy
model = k.models.Sequential([
k.layers.Bidirectional(k.layers.LSTM(units=100, return_sequences=True), input_shape=(None, 1)),
k.layers.Bidirectional(k.layers.LSTM(units=100, return_sequences=True)),
k.layers.TimeDistributed(k.layers.Dense(1))
])
model_name = []
model_name_symbols = {"bidirectional": "BILSTM_1", "bidirectional_1": "BILSTM_2", "time_distributed": "td"}
for l in model.layers:
model_name.append(model_name_symbols.get(l.name, l.name))
model_name = "_".join(model_name)
print(model_name)
for i, (x, y) in enumerate(train_ts_dataset):
print(i, x.numpy().shape, y.numpy().shape)
数据集的形状输出如下:
BILSTM_1_BILSTM_2_td
0 (123, 34, 1) (123, 34, 1)
1 (123, 34, 1) (123, 34, 1)
2 (123, 34, 1) (123, 34, 1)
3 (123, 34, 1) (123, 34, 1)
4 (123, 34, 1) (123, 34, 1)
5 (123, 34, 1) (123, 34, 1)
6 (123, 34, 1) (123, 34, 1)
7 (123, 34, 1) (123, 34, 1)
8 (123, 34, 1) (123, 34, 1)
然后:
_datetime = datetime.datetime.now().strftime("%Y%m%d-%H-%M-%S")
_log_dir = os.path.join(".", "logs", "fit7", model_name, _datetime)
tensorboard_cb = k.callbacks.TensorBoard(log_dir=_log_dir)
model.compile(loss="mae", optimizer=tf.optimizers.Adam(learning_rate=0.001), metrics=[_forecast_mae, _accuracy])
history = model.fit(train_ts_dataset, epochs=100, validation_data=train_ts_dataset, callbacks=[tensorboard_cb])
我一直在研究训练集和验证集的损失函数,但我发现验证集的损失函数小于训练集的损失函数。这可能是欠拟合。然而,我将验证集替换为训练集,以便在训练和测试时监视损失和准确度,但我仍然得到验证准确度大于训练准确度的结果。下面是训练集和验证集的准确性:
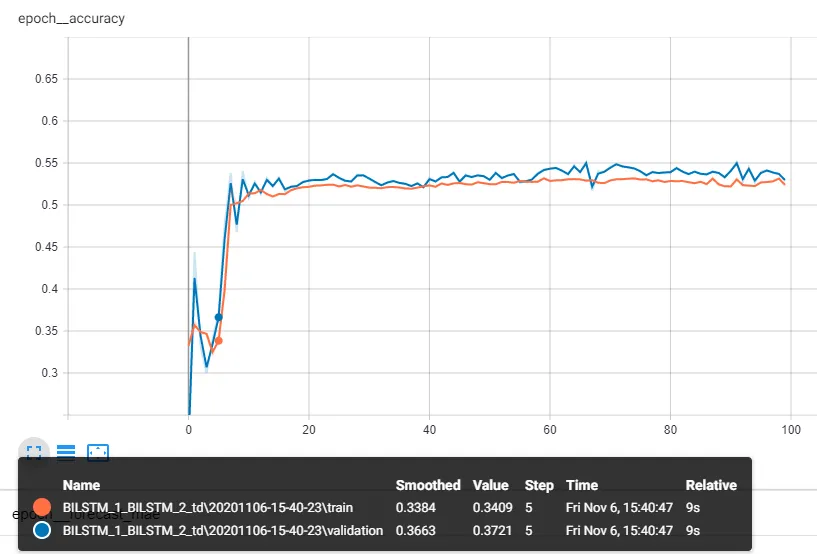
对我来说,很奇怪的是,即使我在训练和测试中使用相同的数据集,我仍然得到比训练准确性更高的验证准确性。而且没有dropout、batchNormalization层等...
请问有什么原因导致这种情况吗?非常感谢您的帮助!
===================================================================
这里对代码进行了一些修改,以检查批处理大小是否有任何影响。此外,为了消除对tf.data.Dataset的疑虑,使用numpy数组作为输入。因此,新代码如下:
custom_train_ts = train_ts.transpose(1, 0)[..., np.newaxis]
custom_train_ts_x = custom_train_ts[:, :window_size, :] # size: 123, window_size, 1
custom_train_ts_y = custom_train_ts[:, -window_size:, :] # size: 123, window_size, 1
custom_valid_ts = valid_ts.transpose(1, 0)[..., np.newaxis]
custom_valid_ts_x = custom_valid_ts[:, :window_size, :]
custom_valid_ts_y = custom_valid_ts[:, -window_size:, :]
custom_valid_ts = (custom_valid_ts_x, custom_valid_ts_y)
其次,为了确保准确度是基于整个数据集计算而非批量大小相关,我将原始数据集直接输入模型,没有进行分批处理。此外,我按如下方式实现了一项自定义指标:
def _accuracy(y_true, y_pred):
# print(y_true) => Tensor("sequential/time_distributed/Reshape_1:0", shape=(None, 34, 1), dtype=float32)
# y_true[-forecast_period:, :] => Tensor("strided_slice_4:0", shape=(None, 34, 1), dtype=float32)
# y_true[:, -forecast_period:, :] => Tensor("strided_slice_4:0", shape=(None, 6, 1), dtype=float32)
_y_pred = y_pred[:, -forecast_period:, :]
_y_pred = tf.reshape(_y_pred, shape=[-1, forecast_period])
_y_true = y_true[:, -forecast_period:, :]
_y_true = tf.reshape(_y_true, shape=[-1, forecast_period])
# MAPE: Tensor("Mean_1:0", shape=(None, 1), dtype=float32)
MAPE = tf.math.reduce_mean(tf.math.abs((_y_pred - _y_true) / _y_true), axis=1, keepdims=True)
accuracy = 1 - MAPE
accuracy = tf.where(accuracy < 0, tf.zeros_like(accuracy), accuracy)
accuracy = tf.reduce_mean(accuracy)
return accuracy
class MyAccuracy(tf.keras.metrics.Metric):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.accuracy_function = _accuracy
self.y_true_lst = []
self.y_pred_lst = []
def update_state(self, y_true, y_pred, sample_weight=None):
self.y_true_lst.append(y_true)
self.y_pred_lst.append(y_pred)
def result(self):
y_true_concat = tf.concat(self.y_true_lst, axis=0)
y_pred_concat = tf.concat(self.y_pred_lst, axis=0)
accuracy = self.accuracy_function(y_true_concat, y_pred_concat)
self.y_true_lst = []
self.y_pred_lst = []
return accuracy
def get_config(self):
base_config = super().get_config()
return {**base_config}
最后,模型编译和拟合如下:
model.compile(loss="mae", optimizer=tf.optimizers.Adam(hparams["learning_rate"]),
metrics=[tf.metrics.MAE, MyAccuracy()])
history = model.fit(custom_train_ts_x, custom_train_ts_y, epochs=120, batch_size=123, validation_data=custom_valid_ts,
callbacks=[tensorboard_cb])
查看Tensorboard中的训练和验证准确度,我得到了以下结果:
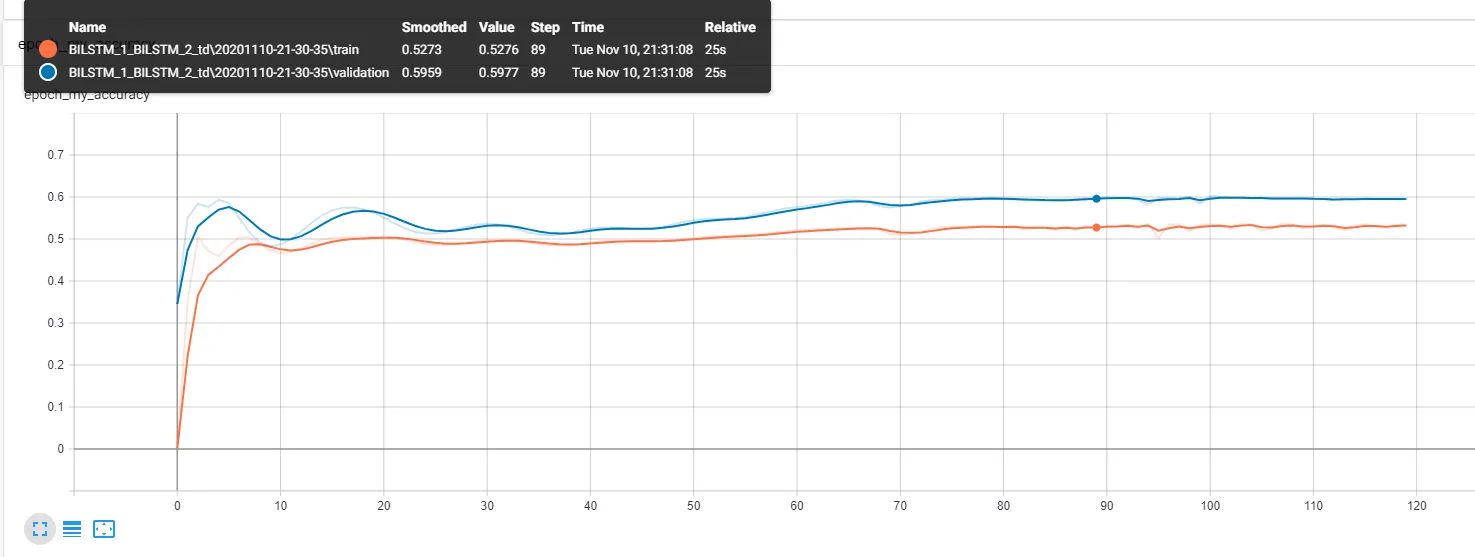
因此,这显然毫无意义。此外,在此情况下,我确保只在调用result()后的纪元末计算准确性。但是,当查看验证损失时,我发现训练损失比验证损失低: