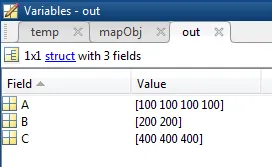
我有一个向量,其中包含值100、200和400。这些值不会混在一起,但它们的顺序可能会不同,例如:
target = [100 100 100 100 200 200 400 400 400];
我希望将这个向量分成三个向量,每个向量都包含同一种值的所有值。
A = [100 100 100 100];
B = [200 200];
C = [400 400 400];
目标长度会不时发生变化,100、200和400的比例也会随之改变。
有什么简单的方法可以分割吗?
这是我的解决方案,但我在想是否有另一种需要更少代码的方法。
columns = size(target, 2);
A = [];
B = [];
C = [];
% Splitting target into groups
for j = 1:columns
if target(1, j) == 100
A = [A, 100];
elseif target(1, j) == 200
B = [B, 200];
elseif target(1,j) == 400
C = [C, 400];
end
end