从标题上来看,我想知道 StratifiedKFold 参数中 shuffle=True 和不加这个参数的区别是什么。
StratifiedKFold(n_splits=10, shuffle=True, random_state=0)
并且
StratifiedShuffleSplit(n_splits=10, test_size=’default’, train_size=None, random_state=0)
使用StratifiedShuffleSplit的好处是什么?
从标题上来看,我想知道 StratifiedKFold 参数中 shuffle=True 和不加这个参数的区别是什么。
StratifiedKFold(n_splits=10, shuffle=True, random_state=0)
并且
StratifiedShuffleSplit(n_splits=10, test_size=’default’, train_size=None, random_state=0)
使用StratifiedShuffleSplit的好处是什么?
在 stratKFolds 中,即使包含 shuffle,每个测试集也不应有重叠。使用 stratKFolds 和 shuffle=True,数据在开始时洗牌一次,然后分成所需的拆分数量。测试数据始终是其中一个拆分,训练数据是其余的拆分。
在 ShuffleSplit 中,数据每次都会被洗牌,然后再拆分。这意味着测试集可能会在拆分之间重叠。
请参见此代码块以了解差异示例。注意 ShuffleSplit 中测试集元素的重叠。
splits = 5
tx = range(10)
ty = [0] * 5 + [1] * 5
from sklearn.model_selection import StratifiedShuffleSplit, StratifiedKFold
from sklearn import datasets
stratKfold = StratifiedKFold(n_splits=splits, shuffle=True, random_state=42)
shufflesplit = StratifiedShuffleSplit(n_splits=splits, random_state=42, test_size=2)
print("stratKFold")
for train_index, test_index in stratKfold.split(tx, ty):
print("TRAIN:", train_index, "TEST:", test_index)
print("Shuffle Split")
for train_index, test_index in shufflesplit.split(tx, ty):
print("TRAIN:", train_index, "TEST:", test_index)
输出:
stratKFold
TRAIN: [0 2 3 4 5 6 7 9] TEST: [1 8]
TRAIN: [0 1 2 3 5 7 8 9] TEST: [4 6]
TRAIN: [0 1 3 4 5 6 8 9] TEST: [2 7]
TRAIN: [1 2 3 4 6 7 8 9] TEST: [0 5]
TRAIN: [0 1 2 4 5 6 7 8] TEST: [3 9]
Shuffle Split
TRAIN: [8 4 1 0 6 5 7 2] TEST: [3 9]
TRAIN: [7 0 3 9 4 5 1 6] TEST: [8 2]
TRAIN: [1 2 5 6 4 8 9 0] TEST: [3 7]
TRAIN: [4 6 7 8 3 5 1 2] TEST: [9 0]
TRAIN: [7 2 6 5 4 3 0 9] TEST: [1 8]
关于何时使用它们,我倾向于在进行任何交叉验证时使用stratKFolds,并且我使用 ShuffleSplit 将数据集分成2份用作训练/测试集。但我相信两者还有其他用例。
StratifiedKFold是KFold的一个变体。首先,StratifiedKFold会对您的数据进行洗牌,然后将数据分成n_splits份。现在,它将使用每个部分作为测试集。请注意,它仅会在拆分之前随机洗牌一次数据。使用 shuffle = True,数据将由您的random_state进行洗牌。否则,数据将由np.random(默认值)进行洗牌。
例如,当n_splits = 4,并且您的数据有3个类别(标签)用于y(因变量)时。4个测试集可以覆盖所有数据而不重叠。
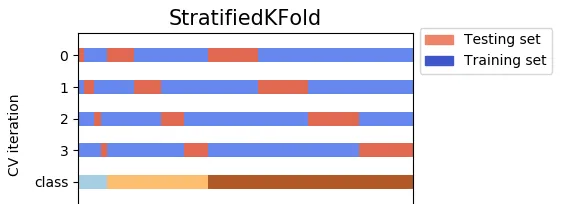
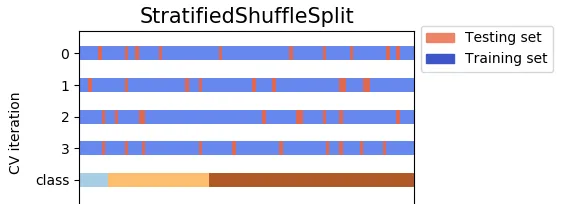
StratifiedKFold仅随机洗牌并分割一次,因此测试集不会重叠,而StratifiedShuffleSplit在每次分割之前都会随机洗牌,并分割n_splits次,测试集可能会重叠。KFold、StratifiedKFold和StratifiedShuffleSplit的输出示例:

上述图片输出是对@Ken Syme代码的扩展:
from sklearn.model_selection import KFold, StratifiedKFold, StratifiedShuffleSplit
SEED = 43
SPLIT = 3
X_train = [0,1,2,3,4,5,6,7,8]
y_train = [0,0,0,0,0,0,1,1,1] # note 6,7,8 are labelled class '1'
print("KFold, shuffle=False (default)")
kf = KFold(n_splits=SPLIT, random_state=SEED)
for train_index, test_index in kf.split(X_train, y_train):
print("TRAIN:", train_index, "TEST:", test_index)
print("KFold, shuffle=True")
kf = KFold(n_splits=SPLIT, shuffle=True, random_state=SEED)
for train_index, test_index in kf.split(X_train, y_train):
print("TRAIN:", train_index, "TEST:", test_index)
print("\nStratifiedKFold, shuffle=False (default)")
skf = StratifiedKFold(n_splits=SPLIT, random_state=SEED)
for train_index, test_index in skf.split(X_train, y_train):
print("TRAIN:", train_index, "TEST:", test_index)
print("StratifiedKFold, shuffle=True")
skf = StratifiedKFold(n_splits=SPLIT, shuffle=True, random_state=SEED)
for train_index, test_index in skf.split(X_train, y_train):
print("TRAIN:", train_index, "TEST:", test_index)
print("\nStratifiedShuffleSplit")
sss = StratifiedShuffleSplit(n_splits=SPLIT, random_state=SEED, test_size=3)
for train_index, test_index in sss.split(X_train, y_train):
print("TRAIN:", train_index, "TEST:", test_index)
print("\nStratifiedShuffleSplit (can customise test_size)")
sss = StratifiedShuffleSplit(n_splits=SPLIT, random_state=SEED, test_size=2)
for train_index, test_index in sss.split(X_train, y_train):
print("TRAIN:", train_index, "TEST:", test_index)
StratifiedKFold无重复抽样,而StratifiedShuffleSplit则会进行洗牌。因此,StratifiedShuffleSplit的一个优点是您可以随意抽样多次。当然,个别样本将会有重叠--因此,在样本上拟合的任何模型都将是相关的--但您可以拟合更多的模型,并且每个模型的数据更多。 - william_grisaitisStratifiedKFold是真正的交叉验证。然而,StratifiedShuffleSplit是一个“生成器”,它会随机生成不同的“训练-测试”拆分,重复n_splits次。 - Bs He